openIDL Navigation
Page History
...
- KS: Recap of 9/26 discussion
- PA - stat plan data comes in, 97 characters, using stat plan handbook, converting coded message, (peter shows data model)
- KS - data models, intake model (stat plan - dont want to alter what carriers HAVE to send, flat text based stat plan when it comes in), stuff to the left
- DR - do it the right way, all pieces could change over time
- PA - not running EP against coded message, keep codes so if you need to do a join
- DR - trust PA to set it up, if he has an idea, assume right answer and move onto pieces we dont have a clear idea on
- PA - ingestion format is stat plan, HDS format is Decoded
- for relational
- 1 record per loss and premium
- for relational
- JM - relational db?
- PA - totally put it in a Relational DB, suggest 1 table per stat plan, dont need to do weird stuff with mult values per column
- KS - claims and prem as well?
- PA - 2 tables per line, ea stat plan has prem format and claim format, main thought utilizing SQL lets biz users to contribute more (Mongo is tricky)
- KS - make decision it is relational
- PA - internal project, if switching to relational has significant implications, when do we want to put that to a formal vote, unpack implications, right now plan is debug first part of auto report, pivot to EPs working with postgresSQL, his team can pivot
- DR no strong opinon on which format but doesnt want to throw out work
- PA - most of the work has been und how the math behind the report and connect w/ business - has spent time learning JS and Mongo, finish up test with Mongo, can design tables and write EP after
- KS - internal planning discussion, JZ wants progress, prove stuff, healthier method
- DR - if saying "lets alter" - wants to make sure reasoning is strong, fine with Mongo
- JM - showstopper if we dont , legion of people using SQL, need to read EPs, team that manages and processes have deep SQL knowl and coverage but no JSON, biz unit comfort seeing relational form of data, ops team who will support forever very comfortable w/ SQL, can't do Mongo
- DR - use Mongo enough
- PA - into relational the whole time, wanted to see it thru with mongo
- DR - TRV can work with SQL
- JB - decide internally, move to relational
- DR - want peter to get resources
- PA - 2 fridays from now, wants to present THEN rewrite stat plans in Postgres
- DR - like postgres (can do JSON blobs directly) - what version?
- PA - still considering
- DR - Which version JSON blog functionality? find out
- JM - postgres favored flavor too
- DR - if we do SQL postgres is worth it
- KS - vetting internally (AAIS), impacts workstreams
- DR - ACTIOn - get Hanover opinion on this stage
- JM - denormalized? keep it flat?
- DR - like that too
- PA - def for the raw tables
- Jm -= challenge of flat, redundancy of data
- DR - performance in terms of speed or data minimization not a big issue here
- DR - node as a service, Peter free range
- JM - EP did nothing but SQL in postgres, highly normalized model, minimal connection, plumbing working
- PA - easiest over all, need stored procedures
- KS - why?
- PA - StoredProcs, do EPs in one lang
- KS - pass in on API call, cant do with stored Procs
- DR - could if you sent in API call and EP and stored as SP and...
- PA - Stored Proc - create and destroy temp views, looping, cursors,
- KS - stored procs are utility functs not part of EP itself?
- JM - zoom out - specifics - what auth do we assume we have over DB? Data management people strict
- DR asking for Vers control over DB, what permissions needed, manual requests? 3rd party agent?
- KS - if we assume only SQL, someone screams we address it
- JM - artifact now - table - can I create/replace (not exactly CRUD), limited # - tables, views, stored procs, etc. - then assume we have the right to create these? EPs can create on the fly? only a table of 7-8 objects, make the grid now - tables and we make em in advance - stored procs on the fly? bigger ask, but have it in this grid
- Objects as rows: Tables, Views, Stored Procedures, Functions, Triggers.
What you can do with them: Create in advance, Alter on the fly.
- Objects as rows: Tables, Views, Stored Procedures, Functions, Triggers.
- DR - look at as optimizations, utility helper functs? get it working with raw queries, I like stored procs - sanitize query, known responsees, good things about them, dont need them RIGHT NOW
- PA - better at SQL than Mongo, depends on how use analyutics node to combine the data, fair bit of process
- DR - do I think we will allow Stored Procs be written? No - dont assume initially
- PA - mid level processing layer, or whole thing in SQL
- DR - willneed midlevel processing long term
- JM - EP needs arb code, third party datasets
- DR - another thing it does help, simpler to maintain vers control of mid level middleware, some funct/procs than DB itself - this way DB is just datastore, need to keep it fed, moves vers control out a little bit, logical separation
- JM as little code in DB as possible, part of challenge - writing code in DB, put it in ETL layer - ETL at Query Time - if you find yourself writing code (stored procs) to get data out..
- KS - reality, people put in EP, thats what they can do in the next year, any updates to StoredProcs, will take forever to get approved by eveyrone
- DR - extensibility of Stored Procs is weaker
- Jm - once DB knows you are selecting, can't drop table in the middle whereas you can with Stored Procs - you can't screw up a db in a select clause but stored proc could blow up db
- PA - use middle layer, rest in JS, middle layer in JS and Postgres?
- DR - no pref
- KS - can we not do this with SQL, can't do this with layers of SQL
- JM - views are a logic layer, opp to put v type layer, dont want to overnormalize, can get rid of redundancy w/ aggregate functions, do you restructure your model, query layer or model in need of adjustment
- KS - governance model and bility to run code that has to be reviewed by people not just SQL knowl, optimize for somethign to be run by people ok'ing something coming across the wire, run into a lot of ugly SQL
- DR - sec architects, they will look at "where is my trust plane", arch whole environ to be secure and only expose DB, only run select statements against DB, more likely to approve something (if something funcky happens outside trust plane, can still protect data easily and will help), if "trust plane is behind DB and expose Data to some procedural code they will raise the bar
- PA - instead of everything in one lang and sql,
- DR - unfortunate process-gated thing, not the ideal engineering solution but where we are stuck
- PA - great discussion, how they look at sec, finish in mongo and do it in postgres, no stored procs, JS to make multiple select queries
- JM - dont mind scary looking sql, run mult subqueries and stitch together at bottom,
- PA - depends on who the person is reading it, simple objects WITH clause gets harder
- JM - do we put VIEW layer on here? is my model correct, team is adamant about keeping flat but can read long sql
- DR - plan there, may or may not need ot be middle layer, assume we dont need and only add if PA says he needs it? or assume we need it
- PA - middle layer to enhance EP?
- DR - third party data enrichment
- PA - entire report puts together,
- KS - assume we haver reference data nearby or not true? all transactional data?
- PA - state names replicate, state codes replicate
- JB - consolidation side
- JM - reporting logic, shouldnt occur here, not in the adapter -
- DR - only getting data over the wire to the servicew
- KS - no PII raw data over the wire, some agg happening here
- JB - cert have codes and dereference with labels later
- JM - where does reference data get resolved?
- PA - sourcing ref data from stat handboiok, on load, human readable when going in ETL: dale submits data, stat records go thru ETL, loaded into Relational data store, take code and add column for RI
- JB - in order to be human readable by carrier?
- KS - less Human readable and more out of AAIS codes and into
- JB - standard iso codes better than labels
- KS - bring it into something more standard
- PA - need to look, believe state codes are NAIC codes
- DR - we now have a plan for DB, plan for what happens after adapter done, unless we need it, role of adapter = accept EP,
- JM - long term design issue - if we do enrichment stuff at the grain of native data?
- KS - a lot of times it will be, have to be able to support it
- JM worried that if you run relational query, rule/val prop - run on fine grain data but arb logic from other data sets needs access to fine grained data, then therefore you extract priv data from RelDB, then filter it down
- DR - 2 trust planes
- SQL first
- Node - as long as it happens on the node, technically palatable, depends on how implementation looks, do we need quarantine zone, middle layer
- JM - opp to review data set NOT JUST EP
- DR - biggest design challenge:
- JM - human interface, there needs a gate somewhere that says "give a human ability to review data before it goes out the door
- DR - still one environ, if passing non agg data over the first trust plane, need secondary stop somewhere
- JM - "no humans" is not good, needs review
- KS - intention - testable dry run in final product
- JM - MVP 1 - dont put it but final product
- DR - same page with James, how to make it secure, one thing queries, will require executing foreign code in a runtime, not written by us, more powerful than SQL query
- JM - two trust planes, will be post-db
- JB - run some carrier side? access to the data
- DR - all on the carrier side, wont be in the node, but thing is the hard line in the sand for Sec - no code execution behind the trust plane (sql queries fine)
- JM - core deliverables - deck for the DB teams of large companies - selling to security people, will be work
- DR - most val artifact that comes out of this, JM/DR tell us what to say
- KS - cant accept solution without this box, they can run it or see results, arbitrary code only SQL (read only)
- JB - worry - some pattern that requires raw level, in the output
- JM - do high risk stuff all the time, but work at it (sharding, encrypting, jump thru hoops)
- DR - homomorphic encrypt for all? (laughs)
- KS - concern, are we back in "TRV does this, HRT does that?"
- JM - need to prove no way to do it simpler, hard fight but make the business case
- DR - always an exception process for sec finding, make as simple as possible b/c variances between teams, more and less strict, avoid needing to ask
- KS - not all will sign on to the risk or have the will to review it
- DR - inconsistency, one carrier agrees to somethign another thinks is risky, will run into, w/in a carrier depends on who reviews case and which CIO (who makes risk call), w/in carrier dont have one standard, decision makers still use judgement (there are still no gos)
...
- JM - Wed Hartford has 2 new people joining effort, leadership allocated, JM still involved, new person on Arch WG, asked for build team for Q1, Q4 is ramp up time
- KS - talked to AAIS about redirecting PA from Mongo to SQL, AAIS is on board, whatever PA is working on should move towards stated direction
- KS - relational DB, run queries that are coming from community, talked about scanner
- KS - across API layer, all running in carrier, no side effect code like SQL, relational DB, allowed to execute against it to return response, deferring scanner and enrichment - did we say defer test facility
- JM - out the door with smallest MVP we can, solid like is core, dotted p2
- KS - ETL, submit stat plan, ETL turns into relational structure, EP Processeor executes SQL, across API and API returns results of that
- JM - is this good enough to turn into diagramn to show that, MVP: hand nothinjg but sql string over interface, Extract Processor, run it get it back, hand it back to interface have end or end plimbing - this is the core
- KS - nuance to execution of SQL, might be more than one sql? pipeline? worth discussin g now? or hope it can all be done in one sql
- JB - script? series of sql statements
- JM - agree it needs to support multiple queries, how do they communicate? pipelines - how do you get tem to talk to each other?
- JB - temporary tables, not modifying (create/destroy) is safer, in addition need to wrap initial investigation of request, step before
- JM - is validator on this side or the other side?
- KS - put it on both, create SQL, validate on the way in, if SQL dont know how it could
- JB - do need to investigate SQL - stat plan can say "gimme report", but other things will require you look at the SQL
- KS - going back to MVP, scanner/validator is out of scope,
- JB - if all doing now is agreening getting data from stat data, all SQL will addrsss, then scanner/validator do somethign simple, no need for consent dialog until we do the basic stuff
- JM - MVP in loosest sense of word or product out the door - can't do product until scanner/validator is done
- KS - MVP or POC?
- JM - sequennce the lines, 1-4 proves it works, 5, 6, 7 go to the industry - if solid line is #1, what should second be - more about proving own assumptions/proving value to industry?
- DH - business perspective, security from going from TRV node thru adapter to analytics node, showing data privacy
- KS - lot og reqs, go and pick the ones that drive second level of POC, things required and implemented before we go to production
- JM - enrichment 4th on my list, of business-y things, scanner-validator says "ok?", test validation says "run 100s of rules to prove it is what you think" or Enrichment?
- DH - prove my data is protected
- KS - the scanner - #s 1 and 2 show security, DH wants to show rest of the flow and across nodes we make sure the stuff is going the right way over analyutics node
- DH - basic plumbing
- JM - end to end plumbing? least I need to do to prove it
- KS - briunging an arch perspective here, 1st thing: does the plumbing work, 2nd can we install in a carrier - imp it will be acceptable in a consistent way across carriers - what we work on here can abstract or work concretely so everyone can run it
- JM - Enrichment is scariest
- KS - needs robust plugin capability or external data model - trust and maintenance are hard, diff timeline than EPs
- JM - stop at dotted line and focus on solid lines, all we are gonna do
- KS - step 1 solid lines, step 2 end to end plumbing, step 3 up for discussion but for KS "does this work in yoru carrier node"
- JM - focus on solid line
- JM - get mult sql problem, need mult sqls, couple ways to solve this, argue this executes out of schema with no data in it, schema that carries data, give s a level of grant writes to DBA team - ask what is the set of writes asking for in sub schema
- KS - can we est a sandbox DB where the EP works, updats, creates tables as necc
- JM - can say that is a design principle and allow implementor to do either - golden -
- KS - sep schema
- JM - pros and cons of each, takes fight out of DBAs
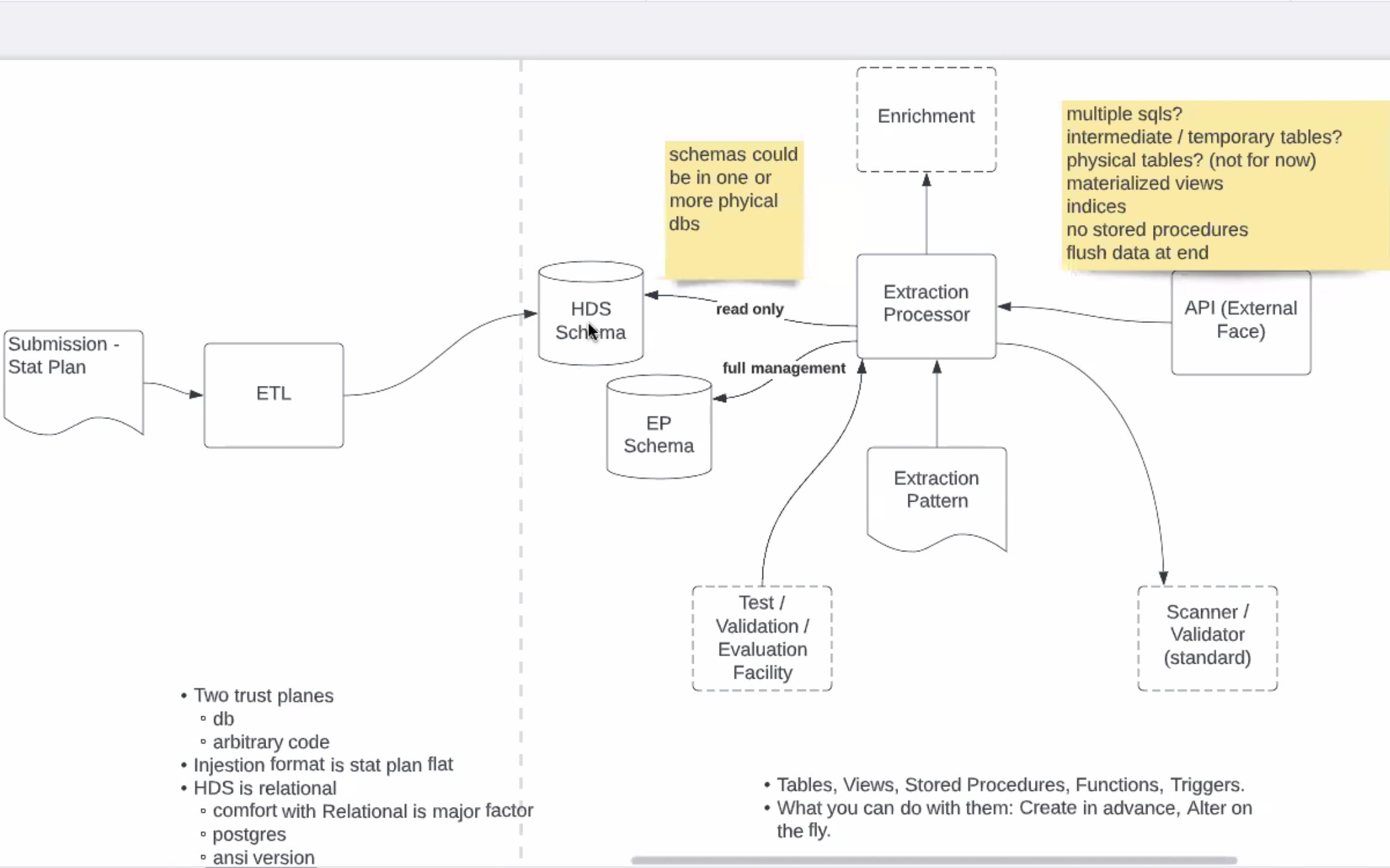
- HDS Schema, EP Schema
- JM - separating easier to ask for things - default: want to create views on the fly, idea of mult sqls, parsing behaviors, smart enough, put it anyway
- KS - could be a collection of strings
- JM - how interacting with each other
- KS - first can retunr, second consume, you test it - sql string updates intermediate table with data, all yo uhave is a coreogrqapher (run first, point second at results)
- JM - intermediate table, SQLs comm with each other, creation of complimentary tables - DBAs protect data - ask for "Create Views" auth OR temporary tables (sometime dont have robust you want), ony talking about views, temp tables or phys tables
- JB - creation of indicies
- JM - assumed, agree not to use Stored Procs, comfortable saying "want schema, in schema have these rights, agree to flush data (flushing policy)
- KS - drop the whole DB
- JB - temp tables when connection closed by default, but drop statements good to do
- JM - might be worth asking for matrialized views
- JB - temp tables for intermediate results
- KS - keep saying not time bound, if we have to do more X not a prob for performance
- JM - if this is a long list we have to ask DBAs for
- KS - assume "yeah", go ahead and create schema, inside POC, extract processor remove/create tables
- JM - grant grant grant - pretty minimal,
- KS - table creates and stuff
- JM - phys table question on there, more pushback, flushed data is question mark
- JM might find optimization opportunities
- JB - consistency issues, better to treat like workspace and flush it
- JM - no phys tables for now, materialize views?
- KS -seems like EP has more complicated interaction diagram, interaction diag between 4 components?
- <Live diagramming>
- JM - view is a mech to make one sql depndent on another sql, materialize view "love the view but need performance", phys tables fix perf issue but need in advance - want to go as far as we can to
- KS - running first sql, get results, where kept?
- JM - temp table, self-destruct at end of session
- KS -DDL?
- JM - easier ask
- KS - go0ignm to have to describe the structure of results so temp table can hold em, has to be done before run first query
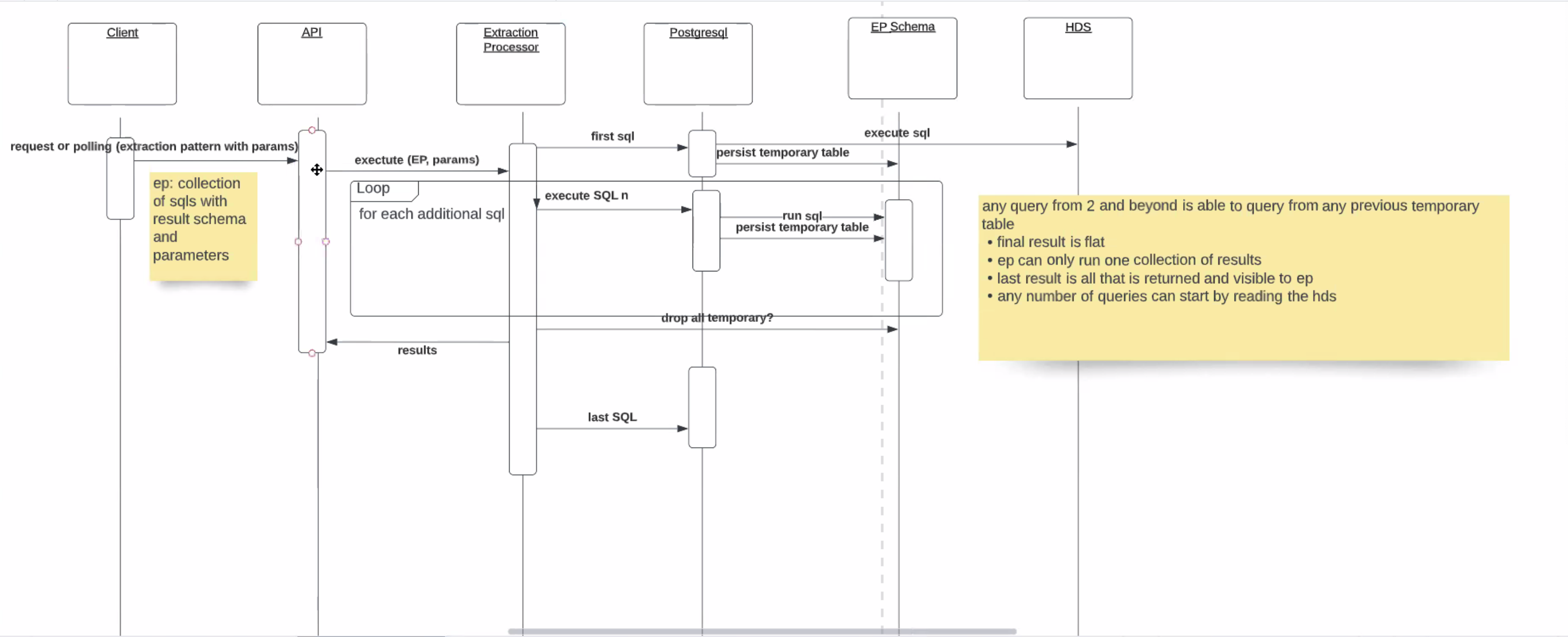
- JM - draw out one query problem - EP should have arrow to postgres SQL and say "SQL", assume it does, will then (logical not phys) will largely read from HDS, retrieve data, postgres to EP schema
- KS - somethign in SQL says "select x from this table " returns result, and persistning temp table?
- JM - retrive from HDS should be enough, in any non trivial case results go in temp table, if we assume we wrote temp table, the Extract Processor runs retrieve
- KS - recap of 10/3 call
- KS - Adapter tab in Lucidchart
- solid lines in first POC / MVP, proving point
- dash lines phase 2 - prove end to end security and privacy
- other MVPs are technology, suitable as a common implementation across carriers, lots of other requirements, executing some reports
- KS - get first couple phases defined, solid lines - decision wanted to make and bring to TSC on thurs, DB will be relational, most likely postgres, dont think phys db is what we will land on as a decision vs what level of sql capabilities it has, needs to be able to do these things, clarifying (exeucte DDL, lot of nuance, temp tables, etc.) - needs to run SQL and SQL queries in modern way, store data in json fields, some extensibility w/o schema migration - will bring to TSC on Thurs as
- PA - JSON in the row could create problems
- KS - not sure but worth discussion, revisit concerns when draw up decision, prob not part of first phase anyways, keep it as a thing to challenge
- KS - what is in first phase (boxes in and out, part of arch running on carrier/carrier footprint)
- API interface
- reach out via scheduling or polling or challenge/response (request from another service: "time to run an extraction"
- resp for taking a request w/ EP on it
- in EP:
- SQL, other things we uncovered (next page)
- parameters, allow to work with diff states
- Extraction Processor
- gets data from HDS
- runs 1 or more SQL
- to provide robust solution might need "pipeline-ish" sorta thing
- shouldn't do any DDL against HDS, DBAs would be ok with this as loing ad DB is unassailed by side effects (new tables, create views, change of data by EP)
- collection of SQLs executing, requires some intermediate spot where first sql goes, picked up by second (see sequence diagram)
- first SQL gets results, to second SQL (requires second schema, allows for temp table to support results of first query)
- Extract Processor -
- result of SQL1 is another schema
- "schema 1 results in this dataset, create temp table to hold it, run first query, store results in temp table, continue process to last SQL and results of last SQL returned
- Submission Stat Plan
- ETL process
- HDS schema: flat, denormalized, relational doesn't have to be exactly stat plan, simpler read, not flat file
- API interface
- KS: James has resources starting when? (Sean to find out), AAIS approved moving from Mongo to relational DBs
- PA - right now doing ETLs with significant amt of JSON, do we want to sep ETL from HDS?
- KS - sep conversation, not required to go to that depth, if Hartford want to help with implementation then gory details
- KS - should have with MVP working software to load data into HDS, process, get result - helps arch in the room w/ what is running on carrier will work, hint the stack is not so onerous it can't be implmented across carriers effectrively
- KS - 2nd MVP
- could embed execution of stat report? original scope, get a stat report working w/ that plan format, way we show the full end to end plumbing is working, show that data priv maintained, see whwre things coming and going,
- KS - sequence diagram / interaction diagram (Adapter Interaction on Ludicchart)
- Client (hosted node)
- requests
- API
- responds, asks Extract Processor to execute EP, mult SQLsparameters, results schema
- Extraction Processor (SQL)
- as we execute for each SQL that comes in,
- Postgres SQL
- EP Schema
- allows create temp tables or views, execute same retrieving
- continue process creating results from each SQL, tells next SQL to use the new table
- creates pipeline
- last SQL retrieves from last temp table and end result goes back to client
- Client (hosted node)
- KS - seems safe, well known technologies, sounds like tech stack has no need for Fabric running here, could be network comms agnostic, reply to a request and execute code (JS?)
- PA - version of Linux in relation to Postgres? thinking what PA will do when he gets back, spin up AMI, bash script to install postgres, way he installs may be different
- KS - EC2 or Lambda - will see
- PA - maybe inside Kubernetes
- KS - Postgres could be hosted too
- PA - using more amazon specific stuff, linux box makes it cloud agnostic
- KS - would like DavidR or JamesM to weigh in on those decisions (suggestions or "we will configure as X"
- PA - general thought, big carrier who roll own solution should but small to midsized want easy to use test environ on their own
- JB - this is partly why we are saying lowest-common denominator SQL
- KS - least controversial technical stack is what we are after
- KS - this is enough for peter to start directing his work when back Monday, can't go deeper on decisions yet, big decision not useing NoSQL and committmeing to relational DB for HDS, bring to TSC thurs and get a vote, tacit approval from DavidR, JamesM
- PA - how about debugging of Mongo to show DMWG it works? continue? plan to present next friday
- JM - persist temp tables for the next SQL, could put "read temp table from EP schema" to be more complete, end of the day SQL code but the BEHAVIOR
- KS - first SQL, might jump straight thru and return results, if other SQL will persist w/ temp table and continue until don't have any more queries, return results, important: allowed to create temp tables on second schema where we can't do that on HDS (HDS is sacred, no side effects, cant change data, cant change schema) - do we want to write in the dropping of schema?
- JM LINK
- KS - every time we run SQL we return results
- JM - evident from diagram to the user the writer of an extract script, only the last SQL will result in results go back to client from API, useful to show in loopbox, that there is a looping behavior for any nymber of SQL for any number of tables
- KS - dropping the table at the end if it collapses you can debug it
- JM - serious implications
- say 8 sql
- first 7 make intermediate tables
- 8 is the only one to make final results
- purpose of intermediate tables is for processing
- all data stays in EP schema but if we show results in the loop at processor level means the data is coming back to Extract processor
- final select statement only one allowed to write back
- intermediate results only live in EP schema
- whole point, only get one result at end of day, designer of EP needs to know
- must drop all after final retrieval query
- simple case - one sql and be done with it? go for it
- http://www.cs.sjsu.edu/~pearce/modules/lectures/uml/interaction/SequenceDiagrams.htm
- first sql, last sql results
- any SQL from #2 and beyond can read from prior temp tables
- some reasonable degree of paralle processing
- rules for writers of EPs
- JB - if results are result sets from last sql statement, flat structures, is there a case where we want to return something w/ structure, serialized result
- JM - if we modularize this write, in future release, you could put loop box around EP +, any one hit of the DB returns 1 table could you loop above (now EP can do mult scripts on mult datasets)
- KS - if you said "read all by zipcode" then "by floodzone" trhen "read together" - link by foreign key - not single flat wide row if each pieces is building more structured model
- JM - if sufficiently modularized once, should be able to do mult times - if you make a rule only last can do output is a functional req, has to have mechanism to know when popping out with results
- KS - last is always flat result set
- JM - throw on day-2 list, agreed denorm is bettrer than norm, etc. - denormalization argument
- KS - will pipeline of SQLs support these reports, sooner we can throw a real pipeline aghainst this model the better
- JM - in question, flat and wide aggregated, sorted, filtered - if mult sqls, EP can run any one against HDS, still wondering how it looks at attributed fine grained data,
- KS - allowing mult SQL to run against HDS (constraint: retrieve read-only queries, one or more tables, any other SQL could read any table created temporarily, eod have one query returned flat 2-dimensional result)
- JM - w/ that design, EP is firing off SQL but not seeing data, only sees final data - downside: mandates single flat table (could see situation where you want more than one table) - the Extract Process might want more than one table - if we say EP must be aware of more than one result set, needs function that allows EP to run any number of datasets, if we only allow EP to be the place to see where it all comes togethe then
- 1 EP sees fine grained data
- 2 will need Py/JS or something up, not SQL to read it
- Ks - unwind it
- the final results could be multiple result sets but combo could also be done in that loop here inside the SQLs if you need to return mult results, EP never has to see fine grained stuff over here
- JM - hybrid
- prescriptive
- say have API and attach DOCS, some # of docs
- allowed to call API w/ any nyumber of docs, in 5 docs is SQL statements, any nyumber of SQLs,
- accountability so that only last one can serve result set
{kind=link}
- Introductions
- KS - TSC decisions, pushback - document arch well, keep track of decisions, only thing TSC needs to hear are things that are controversial or heavy weight (JM: big decision or controversial) - need to document the decisions well, consistently, get sent to archs in the room - lots of frameworks out there, happy to use one that works - what we did for what we have right now
- SEAN BOHAN TO GET MILIND AND MOHAN ACCESS TO LUCIDCHART
- PA - eval of postgres to gen the autocoverage report, state-by-state breakdown of auto ins in the state, spend time TUes meeting on how we do that eval, get aligned and going in a way we all thinks make semse
- JB - feedback from maybe Hanover
- Faheem - SQL server shop
- PA - doing open source stuff here, dont want to put AAIS in position where they need to pay for mult solutions
- JB - if carriers can use compatible sql platform...
- PA - for eval would like to use postgres and how that connects, every implementation of sql is different (setup, strings, lot of similarity), 6 months ago discussing need of mult options, test ex of all, do postgres first, how much we want to use
- PA - walkthrough of the platform
- RDS vs EC2?
- Milind - yes. why? maintenance
- Faheem - better to use managed service than manage this yourself - is the blue box what the carrier maintaines or per carrier in AWS
- PA - blue box (diagram) - each will have their own, segregated account, isolated from rest of enterprise, your infra you will manage, hopefully get to high level of automation where it manages itself
- FZ - if we can as a group propose an automation that works well in AWS, more standardization, more debug, makes sense -
- mostly azure shop, starting cloud journey, how much effects or not
- PA - Hanover is mostly azure, started few years ago - you could because of the adapter connecting into blue box, think to do something in serial-izable way, one could run azure, one could rune somethign else - our enterprise on AWS, more comfortable, initial trial would be idea in AWS
- FZ - are most on AWS?
- JB - should be able to run the network across clouds
- easiest for people to work with, run on azure, fave platform
- FZ - will help to see if it makes more sense for Hanover,
- JB - some of the work oriented towards platform as a service, more than one cloud
- PA - can explian w/ AWS but would like to learn equiv services (like azure) - been working with internal team to deploy existing arch, all in terraform, using service like terraform for deployment for multicloud stuff - using in this box - S3 buckets, serverless functions, bucket storage, S3 in the ETL, system of record outside of the blue box - stat record= string, dep on position or number means diff thing, one for each row, record generated from it - ETL= gen stat records, load into S3, trigger serverless and decode the record, from coded string into json - thnking RDS makes sense
- PA - not where we are exactly, is terraform what we want to use or somethign better?
- PA - premium transaction, policy booked, info about whats being insured - also have loss record, same length - doing it in mongo used one collection (collection_insurance) and used JSON, going forward with Postgres, thinking 1 table for prem transactions and one for loss transactions - nature of way data comes to us: flat tables that cat all this info in one rown
- MZ - not storing json in postscripts
- PA - one column for each attributes, maybe more columns, get stuff like like coverage code that might be "2" (bodily injury), put it in the db, putting coverage code and the human readable one - so we have all keys for joins and agrregations, read-in, loaded-in - going to need service-user ability to write load, sep service user for doing reporting vs ETL
- FZ - operationally keep it sep/secure - what portion of the flow outside of the blue box?
- PA - loading HDS and loading info about HDS, will be where your target for your stat data, regulator comes up with data call, blue box is carrier node
- PA - regulator makes data call, Analytics node works as orchestrator, carriers notified of data call and can like or ignore, after data call has been liked a Stat Agent adds Extract Pattern
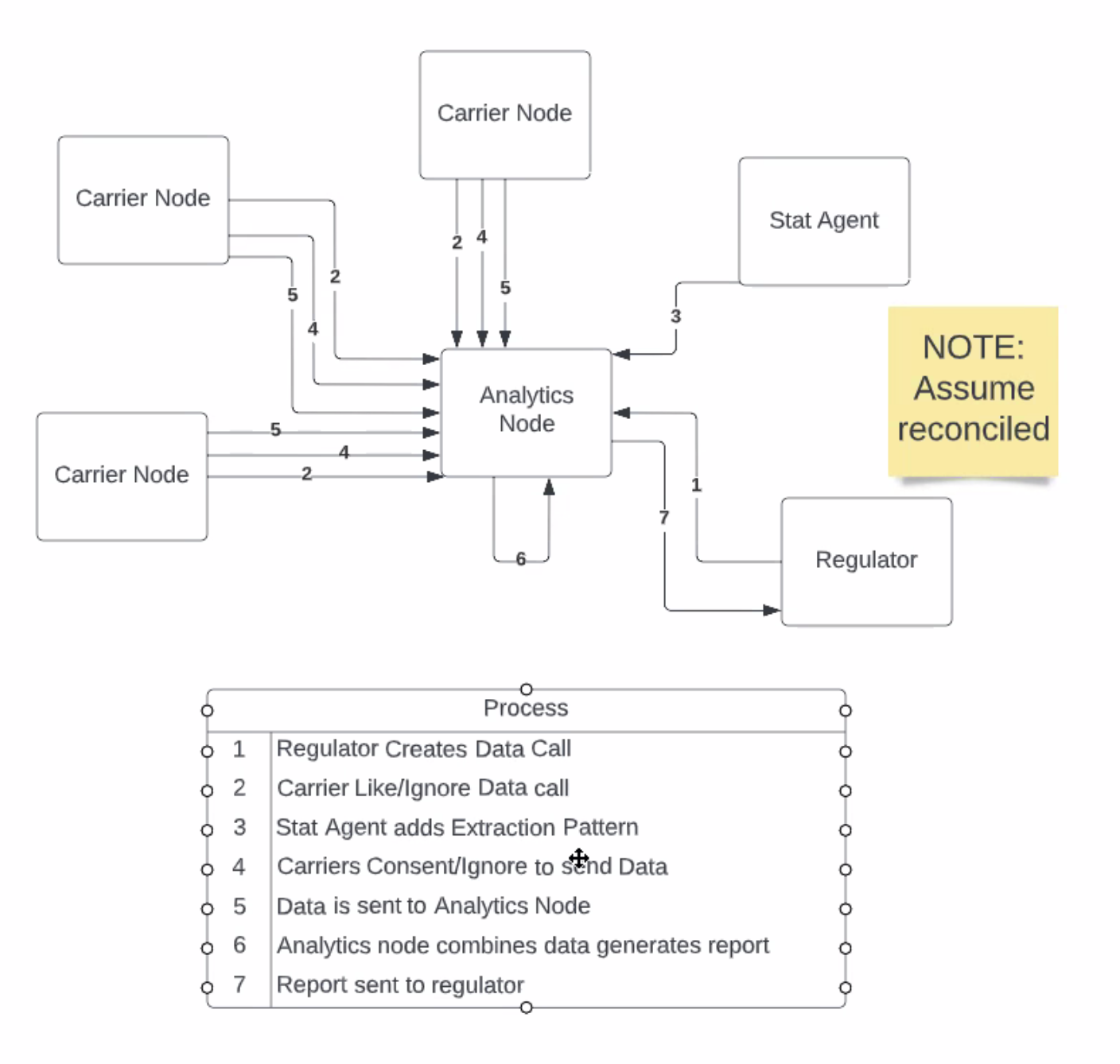
- perfect world all carriers send back data, data always aggregated
- diagram review
- DR - standardize on a SQL engine and store or more cleanly decouple the API from DB, more complicated but bespoke for each carrier - here is a paylod with what we need, standardizes whats avail in HDS, put it all on the carriers to do extract for api call payload OR standardize on an engine - in between solution is allow carrier to decide, API layer doing what it is doing now: passing sql payload, and if you choose to use DB prescribed by openIDL - but if a carrier wants to use another they can write their own inbetween - allow to move fast for this one
- KS - can we guarantee extraction is the same across carriers?
- DR - no less than today, if the HDS is the same across all carriers, intro risk EP written by carrier isn't accurate compared to EPs on nodes
- PA - current workflow the Stat Agent is writing EP, carrier consenting
- DR - writing same thing for mult engines harder - we standardize on engine, stand on API, most carrier just do that - in the corner case wherre comeone refuses or cannot they have option to do it another way and cert data is accurate
- DH - how work? with standard set of queries for stat reporting: fixed, known, unchanging yoy - in this case the EP is unique
- DR - standardize on the output, assume most carriers stand on whats made for them
- JB - ad hoc request relevant - efficiences, need ability to execute SQL, just b/c postfges doesn't mean postgres - create tables and views something a DBA may not want
- DR - an addition, "can we use mult engines?" not sure we can - need to use API extract layer, doesn't think we need to , more palatable to carrier, if rhey cant do data calls efficiently they can revert back to bespoke (their decision)
- DH - value goes away if we can do data calls efficiently
- DR - doesn't change how we interact, from exp there are carreirs who have to use X, if we support too many a problem too
- JB - analysis of what level of SQL is common/needed
- DR - not sure you will find most SQL engines that can use generic sql efectively
- KS - opp to discover
- DR - he is ok with this approach, but in resp to ? "lets expand db engines" - he doesn't think expanding is the way to go
- PA - use time to pivot to notes
- KS - 2 things
- can we defer this decision - doing it in Postgres, ID where there are postgres specific things, ways there is a smaller footprint, und what it looks like, create table structures, do it in postgres, best choice, maybe add in mariaDB, other things
- if we go down postgres, is there somethign we can articulate, or put into docs, "if you do this then..." have we thrown the baby out with the bath water asking people to write their own SQL
- DR - try to make too cloud agnostic, too many abstractions and compromises, go w/ postgres for now, not a bad thing if carriers have to write their own EPs rather than they dont join the platform
- PA - give DBA a postgres compliant EP, they could convert to another engine
- DR - and provide sample dataset to run both against
- KS - if allow them to write their own, give them a testset
- DR - preferred approach, go ahead with postgres, know how to handle this, dont entertain us maintaining us writing mult EPs for diff DBs
- PA - by halloween postgres working, test it against oracle stuff, will do analysis, syntax things, ID whats not compliant with others
- DR - James advocating this approach, looking at complexities - we are good, dont need to make decision now, dont believe if we have to expand access natively supporting EPs is the way to go, provide interface spec and allow carrier to cust as they see fit
- KS - keep efficiency and guarantee all are running the same thing
- DR - doesn't care about EP code, cares about the data model
- KS - diff perspective
- PA - PA HDS

- DR - votes for RDS or Aurora over Kubernetes
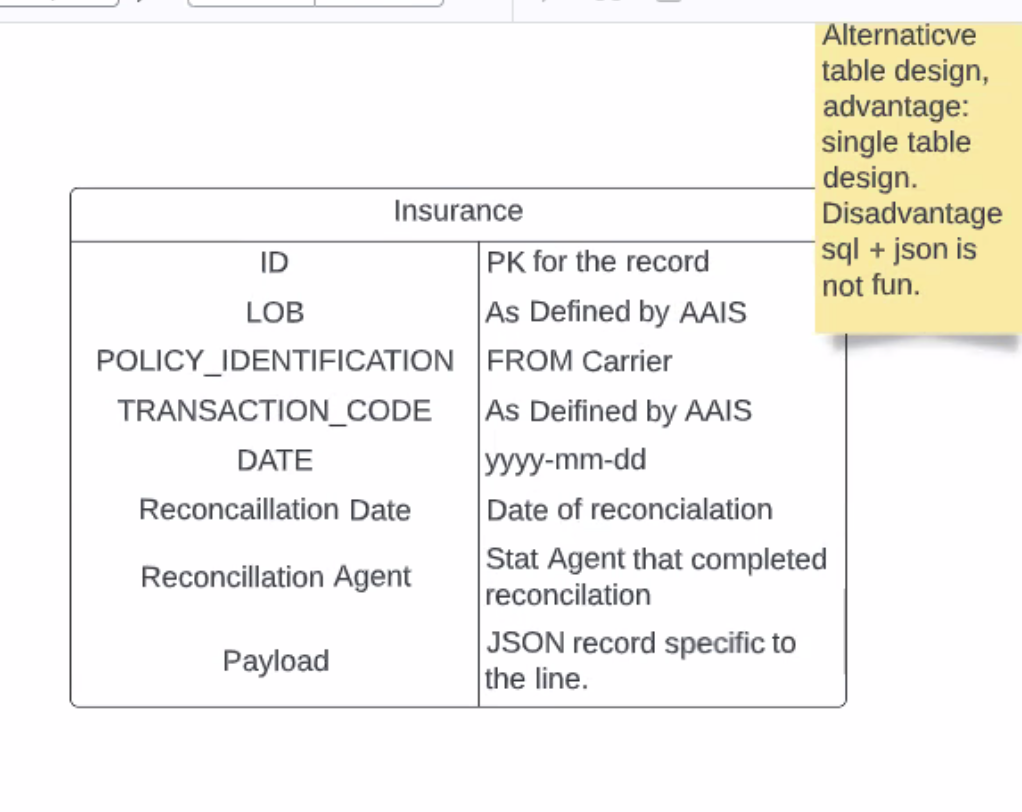
- PA - payload specific to record type as JSON, simpler for loading but more complex for Extract (Sql/JSON not fun) - 2 tables per line (1 prem 1 loss), index tables on LOB/Tracnsact code/date, all scripting goes to main/openidl-hds
- KS - why not just have 3 tables? bunch of overlap between the two, not saying should but working in there, prob 10 or so fields all the same
- PA - accounting date on both of them
- KS - largely denormalized, transactional, single coverage per transact, can be flat, but some overlap between the two
- PA - 2 diff objects and one object per table
- KS - take the common stuff and put it into a 3rd table
- DR - doesn't need to be very performant
- PA - seeing two tables as raw tables, idea of easy to access business level at a later date
- DR - makes sense
- DH - loss divided between outstanding (incurred) and paid - diff transactions - transacrt of paid and incurred total amt expect to pay on that claim
- PA - use views to see those? working on trying to find the most recent outstandings, view layer may be something to look into
- DR - if we use views on day one, may be complex and relied upon
- PA - working under KISS
- DR - views are great, make things easier, sometimes become relied upon
- DH incurred inculed paid while outstanding is "whats left" in a point in time
- KS - can't und suggestion - give diff data?
- DR - lots of use, horrible data warehouses impossible to understand
- PA - use an anon block and do it in a single sql
- KS - script or statement? script, postgres specific
- MZ - I joined this week, so sorry if I am asking repeat questions. In DevOps wiki documentation I saw GIt and versioning strategy. Are we also planning to use similar for data base change and versioning, like using Liquibase? Schema changes?
- KS - too early, single schema, not for POC
- DR - asking for lots of maint and specilaization w/in db, might be tougher, goes to last point, once get more complex then more complex versioning and deployment (accross carriers)
- PA - make sql statements independent of sql scripts, get to maturity we can automate to track DDLs
- KS - looking at stat plans dont get much schema migration, big ask for someone to ask to change schema
- PA - depends how you do it? if we add more columns to end of table wont break existing
- DR - not change is simple or easy - it is a change
- JB - manage over network
- DR - less complex you make it for use to adhere to the more adoption you will get - value to TRV is extracting complexity from them, closer you get the better adoption, more it is a chore to maintain the less adoption and more resistance
- PA - last bullet point, ok w/ location for scripting? make a new dir in openIDL-main
Time | Item | Who | Notes |
|---|---|---|---|
Overview
Content Tools