openIDL Navigation
Page History
...
- bump into challenges and we will describe it
- KS - what should we be talkign about now ? structure of script? Peter? Talk about details of what David brought up (temp structures in postgres? multistep processing?)
- PA:
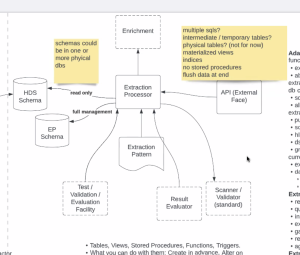
- PA - sub apps/lambda functions, new: openIDL-hds, worked with data engineer, produced table for prem records, 1 col per attribute, mostly varchars, mostly numerics - worked today on loading script, simple, not super fast, havent gotten into making the report yet, delay until we talk to James, brought up Friday, need to add col, unique ID to each record we receive - sequence or GUID? table until James is on the call, will faciliate testing - by next week will have loss and prem loaded, - https://github.com/openidl-org/openidl-main/tree/hds/openidl-hds
- PA - DH and PA looking at metrics and KPIs from data sets, good process
- KS - source data?
- PA - got a company closed, got records from 15 years ago, modified, encrypted and removed identifiers, 10k prem records sanitized and 5k loss records
- KS - source?
- PA - using coded messages - originnal stat plan formmated data, not edited, has been decoded
- DH -cREATED expected values based on the data provide, to test that we ult get it right
- KS - slightly diff than what we gave to DH
- KS - this is the HDS format?
- PA. - table create statement for premium record/auto: https://github.com/openidl-org/openidl-main/blob/hds/openidl-hds/AU_PREMIUM.sql
- KS - EP will run script against HDS to produce one carriers slice of the reslut that is the stat report, data from one carrier's perspective
- PA - earned and summed premiums,
- KS - col by col, needs to be a single script - haven't decided on managed postgres, etc. just that it IS Postgres
- KS - just postgres data source
- PA - once we start looking at how we deploy we look at how/what and then "how is the adapter going to connect", big points of decision
- PA - JS + SQL
- KS - not saying allowing JS to run as part of the extract, as a starting point
- PA - like Python, but chaincode...
- KS -chaincode is in GO, we dont touch, all the code for ui, etc. is in JS - not talking about Kubernetes at this point
- PA - for HDS, dont know enough about adapter or chaincode
- DR - dont think we need kub on carrier side, JS as a lang, py is preferable but dont need to, this is time to discuss "how do we anticipate that working": sql script, return data - what does that look like
- KS - if i were running inside AAIS direct, set up lambda with API gateway and that sit, not sure if it is right direction for this, huge decision, ok saying 'run as a lambda?"
- DR - think so, could also step further and say , the hard part is the SQL script, could extract to point where you say need API, need - api - people will take, lift/load and use it - how do we encapsulate that sql statement?
- KS - plaintext?
- JB - some form of protocol to say what request is to wrap that text, something to create table, sep from extraction, simple message/protocol
- DR - how much is predefined vs extensible - easiest way is dumb API, sends super simple encrypted sql statement, assumes prior knowl of what to expect? fine or need more extensible
- JB - some kind of header or content descriptor, not blindly execute
- DR - could make it more flexible or more hardcoded for lack of a better term - schema vs schemaless, well defined vs open ended
- KS - api results schema is json object or all these fields, assuming going in, one endpoint, having diff endpoint for ea use case wont scale well
- DR - quicker, but wont scale - other ? - is there a need to have a signature of this to verify against? executable code asked to be run - some check needed to check against "yes this is an API call with a query to execute how do I make sure this is the right query"
- DR = some mech by which you say "yes I have an API call and it is what we say it is", maybe built that into auth flow? payload is trusted? thinking what cybersec peopel would want - exec code that returns data - million ways we could do it - do we want somethign to verify the payload is unaltered - simplest a CRC checksum signature kind of thing - if you download my code this is the sig you should get - code wasnt tampered with or you did something goofy - notes it is "RIGHT" and makes sure all are running exact same code against db
- KS - trusting what they are asking is what should be run, high level
- DH - signature both ways? here is what we want you to run and here is what we ran?
- DR - outbound, assume it is all encrypted in transit, have some negotiated key exchange, know it came from us - some kind of handshake - nuance is in one direction there is a party executing code from an outside source, API off-flow, e
- FZ - if altering data, ID of sender and instructions are compatible with what you are sending, if ID and instruction not altering anyhting
- KS - James put forth it should not alter HDS, where we came up with second schema - need to know what that script is gonna do to run against the HDS a
- DR - quick easy check: here is what it is suppsed to do, here is the signature for the code that does X, verify
- JB - session based?
- DR - extra layer, when you run this checksum, code, hash, this is what you should see and if you dont see it something is wrong
- DH - how do we know code is not going to cause any harm to HDS or deleting records, etc.
- PA - compartmentalize the risk, doing reporting, specific users
- DR - down the road more important, running not only against the db, limiting connections
- PA - RDS has features, amount of risk isnt huge
- DR - not huge but also lightweight - hash and publish the hash before running, gives a sense of security and consistency everyone is running exact same code
- PA - signed payload like linux ISO, can pub hash, will have more insight next week, earned prem, small way to show what is req to get here, not too complex, help carriers going thru cyber audits
- KS - if one API vs mult schema oriented apis then generic schema
- DR - the other discussion, not all hash needs to be transmitted over the wire, pointers to docs that desc what it is, dont anticipate feature rich facility at the begininin
- KS - getting somehwere with actual script is the biggest in the near term
- DR - get something to show as soon as possible: API Call Made, Code Run, Results Returned - dont get bogged down day 1, things need to be there, can be handled by references - from carrier perspex that would be good, maybe info is pre-shared or published in advance to keep API logic down
- KS - if we can get James involved, would be good, talk about running the script and that process tomorrow (10/11), did start moving documentation on the wiki to make room for incoming documentation
- PA - (Takes us through the work he has been doing with the test dataset https://github.com/openidl-org/openidl-main/blob/hds/openidl-hds/AU_PREMIUM.sql
- PA - Sequence or GUID
- KS - unique identifiers - who owns the ID? does HDS own it or do we expect outside of HDS to do stuff w/ it
- PA - primary key on record at transact level should never leave your area/priv account/pdc, makes sense to have that decentralized and controlled by HDS
- KS - no other outside systems dependent on it either - for debugging
- JM - benefits of GUID - scalability, ease vs scale, interesting question of how postgres chokes at scale? do we care? put it in a GUID have more parallelism than choking in sequence, load on this is slow and dont mind sequencing or parallelization you are done - if you have a GUID generator throws a 36 byte string guaranteed to be unique and run massively parallel processing - only a scalability question but does complicate things
- PA - misunderstood guid - not a guid for every single carrier but across individual HDS
- KS - do not want to throw out massive parallelism
- JM - GUIDs unique as well, will we ever put together for mult carriers? No, not at transaction level - can we use SEQUENCES on day 1 and keep GUID in mind if you need it
- PA - Milind put the command in to do the guid, can make that happen
- KS - thing you lose with guid is ease of understanding of the key, takes time to work with the guid, has pros and cons, a dev staring this down another thing they need to keep in mind, if using primarily to debug stuff, tend to use GUIds for stuff and uniqueness
- JM - not massively over engineered, make sure seed it correctly,
- MZ - GUID is better

- KS - nothing says must do sequence OR guid, if not hard to create, sequence is unique, guids might be. worth it
- PA - insert 1 vs insert many, doing parallel stuff will be key
- JM - test the hell out of it - no magic, big fancy hashing algo, depends on what you hash: server name, etc.
- PA - will do some work on it
- KS - adapter and API layer, sequence diagram and lost on a couple spots, why do we need a second schema, cant DB do things w/o destruction to the schema
- KS: Guiding forces
- transax processor runs a single sql script - create table-run query, etc.that can do mult steps w/o being destructive to HDS, having a second schema
- how do you get results back to processor
- sep schema is to appease policy reqs that not too much control over hds schema
- split schema for org considerations
- dont want higher power in HDS schema
- PA - stored proc (dead), maybe use anonymous block to have one sql script executed
- JM - talked about simple and ended in complex, the challenge is what gets back to EP, if you execute the sql script (fairly trivial to write big script) - issue is how to get input back to EP - make query as complicated as you want but only get one result back - ? - what if you have more than one table? at some point you need to get info back to EP - it is elegant to say only last query gets to return results - if you have one, fine but what if you have multiples?
- JB - merit in being to accomodate more than one table - argument keeping separate makes it easier to adopt openIDL in the future is a good one
- JM - 2 issues: a. schema separation (org govertnance and security concerns) - day 1 EP submits whole script and you get one table back - there is an interesting question in how to get it back
- KS - DR felt you don't need sep schema
- JM - technically DR is right, design constraint: big orgs nutty about db power, 2 schemas solves org problem, 1/2 dozen operations, set of scary rights DBs worry about results in log discussion
- KS - diff argument, project: make sure we can do something, maybe not MVP but run a single script that can do the stuff we need to do in a single script in HDS and it does work, now lets figure out will it pass muster in policy groups then go to second schema to solve policy issues
- JM - policy question not an empirical question - are DBA teams nutty about power
- KS - for H this is important, for T it didn't seem to be the same level of importance
- PA - for AAIS feels weird to give that level of power to raw tables
- JM - if we have good modular design should be fairly easy to add loops to the base (scripts), design day 2
- JM - ask we dev in highly modular fashion, compnentns have no external coupling, constraining ourselves by removing loop - you have 000s of queries in script, 2 classes
- 1 does something
- 1 returns results
- do there need to be two scripts?
- KS - into the weeds how you return results? populating table?
- JM - n number of queries and commands, lets assume EP in javascript you have DB connection/objects (run these commands), hey engine pls run this query - dml command, return code, run script that can return command, have populated memory struct in javascript, "execute query, return results"
- KS - script or sql command - running a sql script running commands, still able to return results out of script
- JM - dont think we should run a script - "what client am I pusing this through" - resp of EP to scan and submit each query to postgres engine
- KS - differing from yesterday - how do we get results from script? prob can't - jm doesn't want to run script
- JM - challenge is getting results back, run script is easy but if we do needs andother step, run script need to run a client, easy to tell client run script but challenge is getting results back
- PA - if i am runnign script as part of EP, some ID associated, can't i make a table in results schema I loaded up
- KS - need schema to see final table
- JM - no you don't, if i submit EP and has 10 SQLs in it, and tell EP "run scriopt and loop through", runs 1-5, last query returns result set (might create tables, views, drop tables), EP needs some mech to identify which is the query to return result set - some set of commands to set up, set up table and breakdown scripts - design of object has any number of setup commands, singular query command (returns result set) and any number of teardown commands

- KS - back to a collection of commands
- MZ - just using sql commands? track versions?
- JM - currently just commands
- MZ - could have versioning for data definition changes
- KS - initial request might migrate over time
- JM - notion of data versioning is true, HDS has versioning, how do we pass script in, "queries compatible with x", design of scripts/queries is versioning, need ot make sure HDS is aware of version and EP is aware of version and can be compatible
- KS - one case of using collection of commands is just using, run them against postgres engine and last will be the result (one in the middle will be the result, one identified
- JM - mult query patterns at the same time... could get rid of looping entirely if we allow for query commands that return result sets if we interrogate them - any query that starts with "SELECT" returns a result yet - EP loops through all queries in script, hits "select" query
- KS - how do we pass the results of one command to return results
- JM - script writer has to do it, 3 setup commands (create tables, etc.) the EP runs each query doesn't know doesn't care - query writer has to know
- KS - how do you get results out
- JM - EP establishes session, run it, EP writers job to put commands
- PA - will deliver setup and result - three scripts: setup, result
- JM - getting rid of loop, any number of commands can return result sets, EPs obligation to interrogate those queries - if it starts with SELECT returns result - still loop in there thru the commands but super fine grained the loop, instead of looping at script level loop at the command level -
- JM - will look like a script, submit it to a client that submits it to the db, we are becoming the client, we need to loop, no magic, make basic rules (semicolon, blank lines, simple parsing)
- JB - comments in the script
- JM - do we put directives in?
- KS - directives nose under tent
- JB - fragments telling whats in next set
- JM - no command returns result set w/o being called SELECT
- JM - questions of pagination, etc. - if we agree we loop thru every query, when select we result set, MV1 dont return more than 10k rows
- PA - none of the reports we do early will have more than 10k rows
- JM - will have to deal with memory and pagination issues after Day 1 - hide attribution and fine grained info - intermediate should never leave db engine
- KS - if assuming says "select" and captures results - instead of allowing mult returns only last select statement?
- JM - day 1 = one table
- PA - all standard ones will be one table (there are non standards)
- JM - hard part of mult result sets, whats hard is 2-3-4 results sets how do you return via API, maybe we say API returns 3 huge chunks of JSON and the receiver figures it out
- KS - still stuck on SELECT returns result and others
- JM - only select statement returns results
- PA - for all the annual DOI stuff doing, in good position, need to talk to person at AAIS, lot of low hanging fruit with design
- JM - if only have select statement, MVP 1 run one select statement
- JB - flexibility from diff lines of business, combine and consolidate
- PA - do it all with intermediate temp tables
- JM - EOD 100 lines of JS, suprisingly tight, harder to understand than code
- KS - simple in JS,
- PA - other option, Extract would have name to it and fill table based on name, tear table down - result set in persisiten table noted by Extraction
- DH - perm table stored where?
- PA - your HDS
- JM - or the EP schema -
- DH - another thing to consider (maybe day 2) - companies will want to see results of queries run on their data
- JM - had that accounted for (test/eval or scanner validator)
Time | Item | Who | Notes |
|---|---|---|---|
Overview
Content Tools