openIDL Navigation
Page History
...
- KS - diagram shared last week - depiction of how work should flow. Some requirements were embedded in what was said. (Document shared illustrating this).
- KS - high-level: bringing a script in that is parsed into commands. Starts by quering querying HDS, can do intermediate tables for holding successive queries, can return results on any . Can ID of said queries. We can define queries as select statements. Parsing into collection of commands and executing those commands vis-a-vis 1-2 schemas. We will be walking through this today.
- KS Queries only against HDS - can we assume the first query we see goes against HDS and no others will?
- JM - no, but this isn't a problem - it's an asset
- KS - We have to ID say which schema we're querying. JM: correct, but these should be reserved word calibre notions. The schema names are extremely well defined.
- JM - we should prefix them with unusual enough names that it will forestall an issue, prescribed in a hard-coded manner, so that they can be used again and again. We should be highly prescriptive. Decision: openidl_base, openidl_ep. Select will identify We will require that the select identifies the schema. JM: another aspect: the application user will running the query can only select from the base, much more authority in the EP schema. KS: in fact, user will have select authority against both, but only more advanced rights against EP.
- KS: Only really one of these that is required - the initial select. Everything else is optional.
- KS: how do we draw in sequence diagram? JM: open session doesn't actually go to schema - it's at the PostgreSQL engine running so it can be taken out. Sufficiently accurate to say you're creating tables in EP schema, such that you may select against the base. When we get to the level of depth detail where any more depth doesn't give us add'l insights into requirements, we can stop there.
- KS: will take corresponding modifications tweaking offline. (PA asked KS to pull link to Github from chat, and PA shared screen)
- PA: Everything is in the path, so the premium amount is the actual amount.
- PA: in a really perfect situation, this is all in a perfect situation, this is all we need to produced earned premium:
- PA: Earned premium is not really about one's data set, but about EP within a certain timebound. To get this, we take earned premium/months covered. This is very basic, and data set will never be one like this.
- PA: Working with SQL - hard to utilize parameters without an extremely advanced client. I have start dates and end dates, and strings, but they are parameterized when actually used.
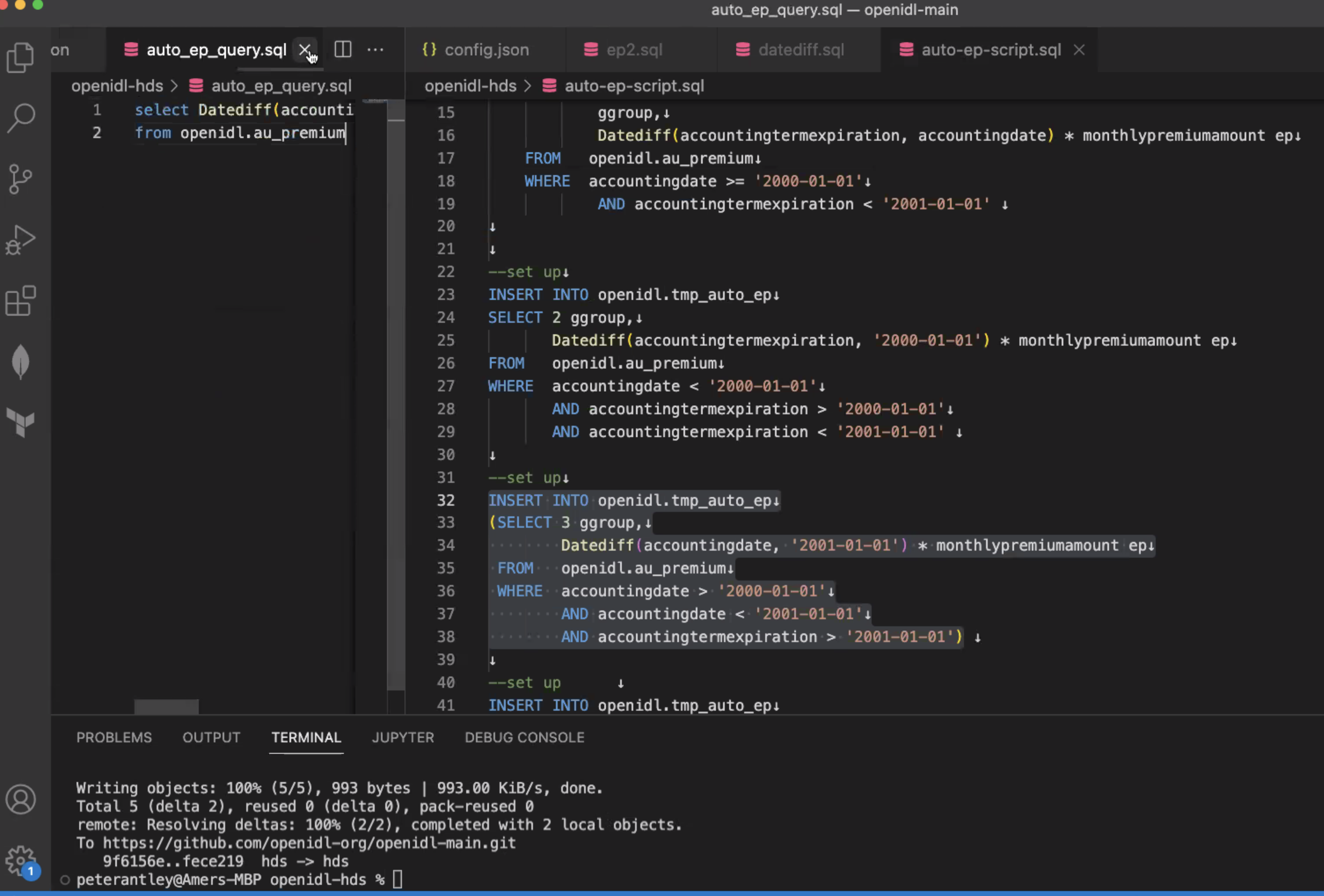
- PA: We begin by running a setup command and creating a temp table, called Temp Auto & Earned Premium. Begin calculating group 1, group 2, group 3, only 1 creates the table, next ones insert into that table.
- Extraction for EP comes down to selecting sum from temp table. Teardown at end is drop of 1 table. 8 columns - EP is first column. Next column is EP Second part - not only earned premium but EP by coverage - so column by column. So breakdown will expand significantly over time.
- KS: current path is sufficiently robust to implement this. PA: this is actually a single select statement (KS pointed out not a single select to implement the whole thing).
- KS: Line 14 - this is a create table statement not a select statement. We have to recognize HDS schema request as a select statement. Break it up in the script
- PA: What we need to do is take these commands, break them down, and separate parse them into objects - e into queries with semicolons.
- KS: This will not work - won't come up as a select statement. We therefore need to break it up into script, yes?
- JM: No, will be fine -after tokenizing this, where each token = this each token represents a query, we just show first token. Responsibility within that larger query. Show the first token within those larger tokens - if it's select, it will do something, but it doesn't matter, because it's the responsibility of the query writer to show identify the two schemas in question.
- JM: All scripts assume their default schema is going to be openIDL_ep - we only specify schema for occasions that involve reaching out to base schema. We leave it blank. Because it is so common to reference EP schema
- JM: but in creating base schemas we want to specify schema name, absolutely. (KS: this happens outside of extraction execution. PA: but pivotal in setting up HDS).
- PA: we process records differently depending on when they fall in the year.
- JM: This demonstrates the case of being able to make intermediate tables. For people who have to read it comprehensibility is a must. PA: for EP - could make more sense to utilize a function and build it differently.
- JM: for scalability & modularity, the desire for functions explains the need for separation (HDS)
- PA: with a test set, we can establish a high confidence level that functions are working correctly.
- JM: single function business point for every business rule. Functions should be defined in either the base schema or EP schema but not borne into extraction patterns.
- JM: if we can put business logic into code modules, we will see repetition even within functions that need to be tabularized. This will put us in a highly scalable architecture/part of a scalable solution.
- JM: this is critical if we ask Mr. Antley and others to start coding
- JM: We also ask selves if functions should be built into base data? PA: can't do w/ETL time - until we know what our bounds are we can't calculate the results.
- JM: We should assume we want to use functions at this point. PA: functions should be part of bedrock infrastructure, not incorporated at query time, or SQL query will get so large that most people can't even read it.
- PA: with the power of functions, I can do one select statement and get results comparable to auto coverage report. Functions we're talking about right now will be created before extraction is run, + validated and tested
- KS: Disagreed because we have to govern those functions and install them. Doesn't believe this is the right approach - we want to keep it as simple as possible and just run the script
- PA: we have to do governance regardless, and not many functions made. e.g., 10 functions, tested, validated, and used repeatedly. The amount of testing done w/extraction patterns goes up exponentially without the use functions.
- KS: not challenging logic but timing. Doesn't believe we need to go there for the MVP. KS: More complicated parsing. PA: but we would set a delimiter.
- PA: we are likely taking about 9 functions. First is DateDiv (2 iso dates - difference btwn dates/months). 1 function for each column in that table.
- JM: if we can develop a set of functions that map cleanly to business requirements - lucid enough that any businessperson can read it, this represents a huge strength.
- KS: we've added a significant dependency on strong governance. Latest version at any time will be necessary for a user to run extraction patterns. Key consideration. (Potential drawback)
- JM: but no worse than the fact that we'll need to govern it anyway. Without functions, all logic has to fit inside extraction patterns. Then we have to add more and more to script, we could end up with massive extraction patterns. Massive prework to get one basic result. Ignores our ability to take advantage of the inevitable repetition within our codes. Also creates issues with versioning.
...
Overview
Content Tools