openIDL Navigation
Page History
...
- PA - (Takes us through the work he has been doing with the test dataset https://github.com/openidl-org/openidl-main/blob/hds/openidl-hds/AU_PREMIUM.sql
- PA - Sequence or GUID
- KS - unique identifiers - who owns the ID? does HDS own it or do we expect outside of HDS to do stuff w/ it
- PA - primary key on record at transact level should never leave your area/priv account/pdc, makes sense to have that decentralized and controlled by HDS
- KS - no other outside systems dependent on it either - for debugging
- JM - benefits of GUID - scalability, ease vs scale, interesting question of how postgres chokes at scale? do we care? put it in a GUID have more parallelism than choking in sequence, load on this is slow and dont mind sequencing or parallelization you are done - if you have a GUID generator throws a 36 byte string guaranteed to be unique and run massively parallel processing - only a scalability question but does complicate things
- PA - misunderstood guid - not a guid for every single carrier but across individual HDS
- KS - do not want to throw out massive parallelism
- JM - GUIDs unique as well, will we ever put together for mult carriers? No, not at transaction level - can we use SEQUENCES on day 1 and keep GUID in mind if you need it
- PA - Milind put the command in to do the guid, can make that happen
- KS - thing you lose with guid is ease of understanding of the key, takes time to work with the guid, has pros and cons, a dev staring this down another thing they need to keep in mind, if using primarily to debug stuff, tend to use GUIds for stuff and uniqueness
- JM - not massively over engineered, make sure seed it correctly,
- MZ - GUID is better

- KS - nothing says must do sequence OR guid, if not hard to create, sequence is unique, guids might be. worth it
- PA - insert 1 vs insert many, doing parallel stuff will be key
- JM - test the hell out of it - no magic, big fancy hashing algo, depends on what you hash: server name, etc.
- PA - will do some work on it
- KS - adapter and API layer, sequence diagram and lost on a couple spots, why do we need a second schema, cant DB do things w/o destruction to the schema
- KS: Guiding forces
- transax processor runs a single sql script - create table-run query, etc.that can do mult steps w/o being destructive to HDS, having a second schema
- how do you get results back to processor
- sep schema is to appease policy reqs that not too much control over hds schema
- split schema for org considerations
- dont want higher power in HDS schema
- PA - stored proc (dead), maybe use anonymous block to have one sql script executed
- JM - talked about simple and ended in complex, the challenge is what gets back to EP, if you execute the sql script (fairly trivial to write big script) - issue is how to get input back to EP - make query as complicated as you want but only get one result back - ? - what if you have more than one table? at some point you need to get info back to EP - it is elegant to say only last query gets to return results - if you have one, fine but what if you have multiples?
- JB - merit in being to accomodate more than one table - argument keeping separate makes it easier to adopt openIDL in the future is a good one
- JM - 2 issues: a. schema separation (org govertnance and security concerns) - day 1 EP submits whole script and you get one table back - there is an interesting question in how to get it back
- KS - DR felt you don't need sep schema
- JM - technically DR is right, design constraint: big orgs nutty about db power, 2 schemas solves org problem, 1/2 dozen operations, set of scary rights DBs worry about results in log discussion
- KS - diff argument, project: make sure we can do something, maybe not MVP but run a single script that can do the stuff we need to do in a single script in HDS and it does work, now lets figure out will it pass muster in policy groups then go to second schema to solve policy issues
- JM - policy question not an empirical question - are DBA teams nutty about power
- KS - for H this is important, for T it didn't seem to be the same level of importance
- PA - for AAIS feels weird to give that level of power to raw tables
- JM - if we have good modular design should be fairly easy to add loops to the base (scripts), design day 2
- JM - ask we dev in highly modular fashion, compnentns have no external coupling, constraining ourselves by removing loop - you have 000s of queries in script, 2 classes
- 1 does something
- 1 returns results
- do there need to be two scripts?
- KS - into the weeds how you return results? populating table?
- JM - n number of queries and commands, lets assume EP in javascript you have DB connection/objects (run these commands), hey engine pls run this query - dml command, return code, run script that can return command, have populated memory struct in javascript, "execute query, return results"
- KS - script or sql command - running a sql script running commands, still able to return results out of script
- JM - dont think we should run a script - "what client am I pusing this through" - resp of EP to scan and submit each query to postgres engine
- KS - differing from yesterday - how do we get results from script? prob can't - jm doesn't want to run script
- JM - challenge is getting results back, run script is easy but if we do needs andother step, run script need to run a client, easy to tell client run script but challenge is getting results back
- PA - if i am runnign script as part of EP, some ID associated, can't i make a table in results schema I loaded up
- KS - need schema to see final table
- JM - no you don't, if i submit EP and has 10 SQLs in it, and tell EP "run scriopt and loop through", runs 1-5, last query returns result set (might create tables, views, drop tables), EP needs some mech to identify which is the query to return result set - some set of commands to set up, set up table and breakdown scripts - design of object has any number of setup commands, singular query command (returns result set) and any number of teardown commands

- KS - back to a collection of commands
- MZ - just using sql commands? track versions?
- JM - currently just commands
- MZ - could have versioning for data definition changes
- KS - initial request might migrate over time
- JM - notion of data versioning is true, HDS has versioning, how do we pass script in, "queries compatible with x", design of scripts/queries is versioning, need ot make sure HDS is aware of version and EP is aware of version and can be compatible
- KS - one case of using collection of commands is just using, run them against postgres engine and last will be the result (one in the middle will be the result, one identified
- JM - mult query patterns at the same time... could get rid of looping entirely if we allow for query commands that return result sets if we interrogate them - any query that starts with "SELECT" returns a result yet - EP loops through all queries in script, hits "select" query
- KS - how do we pass the results of one command to return results
- JM - script writer has to do it, 3 setup commands (create tables, etc.) the EP runs each query doesn't know doesn't care - query writer has to know
- KS - how do you get results out
- JM - EP establishes session, run it, EP writers job to put commands
- PA - will deliver setup and result - three scripts: setup, result
- JM - getting rid of loop, any number of commands can return result sets, EPs obligation to interrogate those queries - if it starts with SELECT returns result - still loop in there thru the commands but super fine grained the loop, instead of looping at script level loop at the command level -
- JM - will look like a script, submit it to a client that submits it to the db, we are becoming the client, we need to loop, no magic, make basic rules (semicolon, blank lines, simple parsing)
- JB - comments in the script
- JM - do we put directives in?
- KS - directives nose under tent
- JB - fragments telling whats in next set
- JM - no command returns result set w/o being called SELECT
- JM - questions of pagination, etc. - if we agree we loop thru every query, when select we result set, MV1 dont return more than 10k rows
- PA - none of the reports we do early will have more than 10k rows
- JM - will have to deal with memory and pagination issues after Day 1 - hide attribution and fine grained info - intermediate should never leave db engine
- KS - if assuming says "select" and captures results - instead of allowing mult returns only last select statement?
- JM - day 1 = one table
- PA - all standard ones will be one table (there are non standards)
- JM - hard part of mult result sets, whats hard is 2-3-4 results sets how do you return via API, maybe we say API returns 3 huge chunks of JSON and the receiver figures it out
- KS - still stuck on SELECT returns result and others
- JM - only select statement returns results
- PA - for all the annual DOI stuff doing, in good position, need to talk to person at AAIS, lot of low hanging fruit with design
- JM - if only have select statement, MVP 1 run one select statement
- JB - flexibility from diff lines of business, combine and consolidate
- PA - do it all with intermediate temp tables
- JM - EOD 100 lines of JS, suprisingly tight, harder to understand than code
- KS - simple in JS,
- PA - other option, Extract would have name to it and fill table based on name, tear table down - result set in persisiten table noted by Extraction
- DH - perm table stored where?
- PA - your HDS
- JM - or the EP schema -
- DH - another thing to consider (maybe day 2) - companies will want to see results of queries run on their data
- JM - had that accounted for (test/eval or scanner validator)
Mon., Oct. 24, 2022
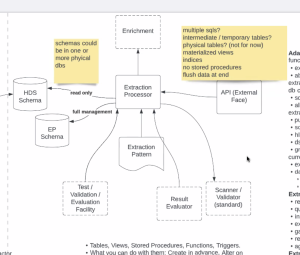
- KS - diagram shared last week - depiction of how work should flow. Some requirements were embedded in what was said. (Document shared illustrating this).
- KS - high-level: bringing a script in that is parsed into commands. Starts by querying HDS, can do intermediate tables for holding successive queries, can return results on any of said queries. We can define queries as select statements. Parsing into collection of commands and executing those commands vis-a-vis 1-2 schemas. We will be walking through this today.
- KS Queries only against HDS - can we assume the first query we see goes against HDS and no others will?
- JM - no, but this isn't a problem - it's an asset
- KS - We have to say which schema we're querying. JM: correct, but these should be reserved word calibre notions. The schema names are extremely well defined.
- JM - we should prefix them with unusual enough names that it will forestall an issue, prescribed in a hard-coded manner, so that they can be used again and again. We should be highly prescriptive. Decision: openidl_base, openidl_ep. We will require that the select identifies the schema. JM: another aspect: the application user running the query can only select from the base, much more authority in the EP schema. KS: in fact, user will have select authority against both, but only more advanced rights against EP.
- KS: Only really one of these that is required - the initial select. Everything else is optional.
- KS: how do we draw in sequence diagram? JM: open session doesn't actually go to schema - it's at the PostgreSQL engine running so it can be taken out. Sufficiently accurate to say you're creating tables in EP schema, such that you may select against the base. When we get to the level of detail where any more depth doesn't give us add'l insights into requirements, we can stop there.
- KS: will take tweaking offline. (PA asked KS to pull link to Github from chat, and PA shared screen)
- PA: Everything is in the path, so the premium amount is the actual amount.
- PA: in a really perfect situation, this is all we need to produced earned premium:
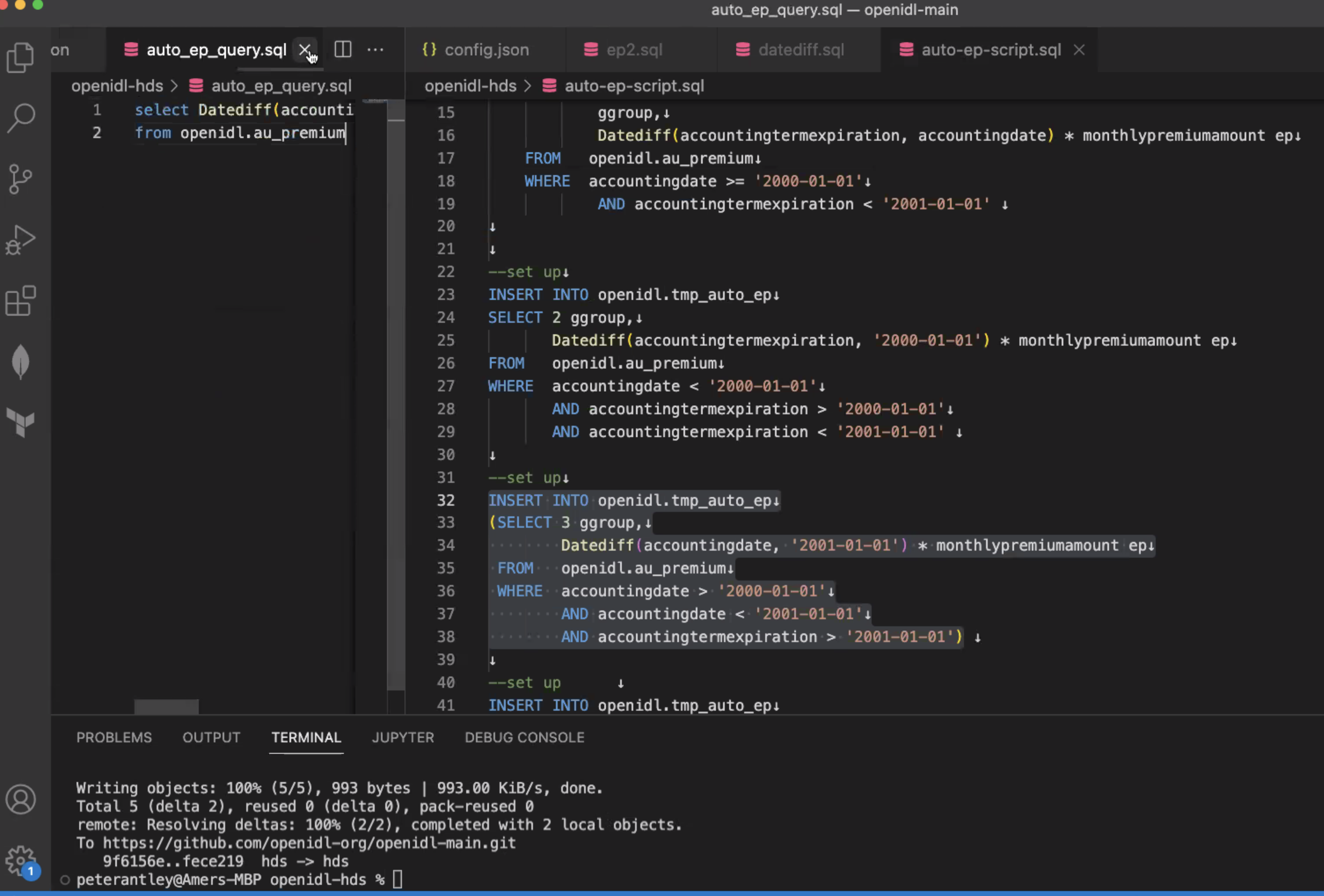
- PA: Earned premium is not really about one's data set, but about EP within a certain timebound. To get this, we take earned premium/months covered. This is very basic, and data set will never be one like this.
- PA: Working with SQL - hard to utilize parameters without an extremely advanced client. I have start dates and end dates, and strings, but they are parameterized when actually used.
- PA: We begin by running a setup command and creating a temp table, called Temp Auto & Earned Premium. Begin calculating group 1, group 2, group 3, only 1 creates the table, next ones insert into that table.
- Extraction for EP comes down to selecting sum from temp table. Teardown at end is drop of 1 table. 8 columns - EP is first column. Second part - not only earned premium but EP by coverage - column by column. So breakdown will expand significantly over time.
- KS: current path is sufficiently robust to implement this. PA: this is actually a single select statement (KS pointed out not a single select to implement the whole thing).
- KS: Line 14 - this is a create table statement not a select statement. We have to recognize HDS schema request as a select statement.
- PA: What we need to do is take these commands, break them down, and separate parse them into objects - e into queries with semicolons.
- KS: This will not work - won't come up as a select statement. We therefore need to break it up into script, yes?
- JM: No, will be fine -after tokenizing this each token represents a query, within that larger query. Show the first token within those larger tokens - if it's select, it will do something, but it doesn't matter, because it's the responsibility of the query writer to identify the two schemas in question.
- JM: All scripts assume their default schema is going to be openIDL_ep - we only specify schema for occasions that involve reaching out to base schema.
- PA: But when we're doing the create statement for EP... we should go openIDL_ep?
- JM We leave it blank. Because it is so common to reference EP schema
- PA: I'm talking more when I create the database.
- JM: but in creating base schemas we want to specify schema name, absolutely. (KS: this happens outside of extraction execution. PA: but pivotal to do this in setting up HDS).
- KS: The default schema then is the EP schema, therefore it doesn't have to be mentioned anywhere even though it can be but doesn't have to be.
- PA: It may be that we start to have some persistent more advanced tables in EP - recurring structures.
- JM: This proves our point and this is exactly what this code tends to look like in terms of business logic. From a pattern perspective, there is different logic for 1 2 3 4, correct?
- PA: Correct. We process records differently depending on when they fall in the year vs. where they are extracted.
- JM: This is a source of confusion - i.e., what is the difference between line 25 and line 34. (He got clarity on this).
- JM: This demonstrates the case of being able to make intermediate tables. For people who have to read it comprehensibility is a must.
- PA: For EP - could make more sense to utilize a function and build it differently.
- JM: For scalability & modularity, the desire for functions explains the need for EP schema separation from the HDS/base schema. It points to repeat question of should this be in the extraction patterns or DB definition?
- PA: For auto, with earned premium, if we have this, and the corresponding function exists in the architecture, we can have a good test set and a high level of confidence that the function works correctly.
- JM: Business rule management is critical here. One of the requirements from business people: they have to be able to manage these rules and comprehend them in a useable way. If we can start getting acute granularity - 1:1 on requirements and functions - there should be a single functional entry point for every designated business rule. This is incredibly powerful re: the scalability of human comprehension. Functions should be defined in either the base schema or EP schema but not buried into extraction patterns. They are too stable across time.
- PA: We're going down an interesting path that will put us in the realm of metadata-driven architectures or table-driven architectures.
- JM: we can put business logic into code modules, aligned to business requirements in written form, we will see repetition even within functions that need to be tabularized. This will put us in a highly scalable architecture/part of a scalable solution. We can talk later about how much we will scale them.
- JM: this is critical if we ask Mr. Antley and others to start coding - a key differentiation.
- JM: We also ask selves if functions should be built into base data? It's not uncommon to venture down a path where we ask if we can do this with ETL time.
- PA: we can't do this w/ETL time - until we know what our bounds are, we can't calculate the results.
- JM: We should assume we want to use functions at this point.
- PA: a ltd # of functions should be part of bedrock infrastructure from outset, but not created at query time, otherwise SQL query will get so large that most people can't even read it.
- PA: With the power of functions, I can do one select statement and get results comparable to auto coverage report. Functions we're talking about right now will be created before extraction is run, + validated and tested. So we aren't creating functions at run time. They will be built into the database and utilized.
- KS: Disagreed strongly with this, because we have to govern those functions and install them. Doesn't believe this is the right approach - we want to keep it as simple as possible and just run the script. Doesn't see the value of creating these elements ahead of time if we can create them as part of the script.
- PA: we have to do governance regardless, and not many functions made. e.g., 10 functions, a test bank to prove they are correct - govern these far more easily than, say, giving someone the ability to create the function at runtime. The amount of validate done w/extraction patterns goes up exponentially without the use functions.
- JM: the idea that we're codifying a certain body of knowledge in a schema is fairly standard. The logic has to exist somewhere - question is not does it need to exist, but where do we put it. Schema definition - putting it in the schema build - is a much more stable location. The question: does the pace of change match the pace of the place where we put it. Pace of extraction patterns - extremely high and dynamic and different every time.
- KS: not challenging logic but timing. Doesn't believe we need to go there for the MVP. More complicated parsing.
- PA: the amount of renaming (reformatting semicolons, etc.) is overwhelming. But we would set a delimiter.
- PA: we are likely taking about 9 functions. First is DateDiv (takes 2 iso dates - givess us difference btwn dates/months). 1 function for each column in that table.
- JM: If we can develop a set of functions that map cleanly to business requirements - lucid enough that any businessperson can read it - this represents a huge strength.
- KS: we've added a significant dependency on strong governance. If the code is in the install base, the latest version at any time will be necessary for a user to run extraction patterns. Key consideration. (Potential drawback) We just put a huge burden on everyone having the latest version of these helper functions. Very concerned about the governance here - ensuring functions get into nodes, and making sure everyone's nodes are updated.
- JM: but no worse than the fact that we'll need to govern it anyway, and there will be versioning regardless. We will have the same challenges regardless. Without functions, all logic has to fit inside extraction patterns. Then the database is humble, we have to add more and more to script w/additional calculations, we could end up with massive extraction patterns. Massive pre-work to get one basic result. Ignores our ability to take advantage of the inevitable repetition within our codes.
- JB: We will have governance-related obligations on the database anyway. Changes will be less frequent than we fear - may only be once or twice a year. Stability is key. JB wants to try to put a higher-level overview on our discussion -re: impact of the adapter wrt its functionality and the operations it might need to perform.
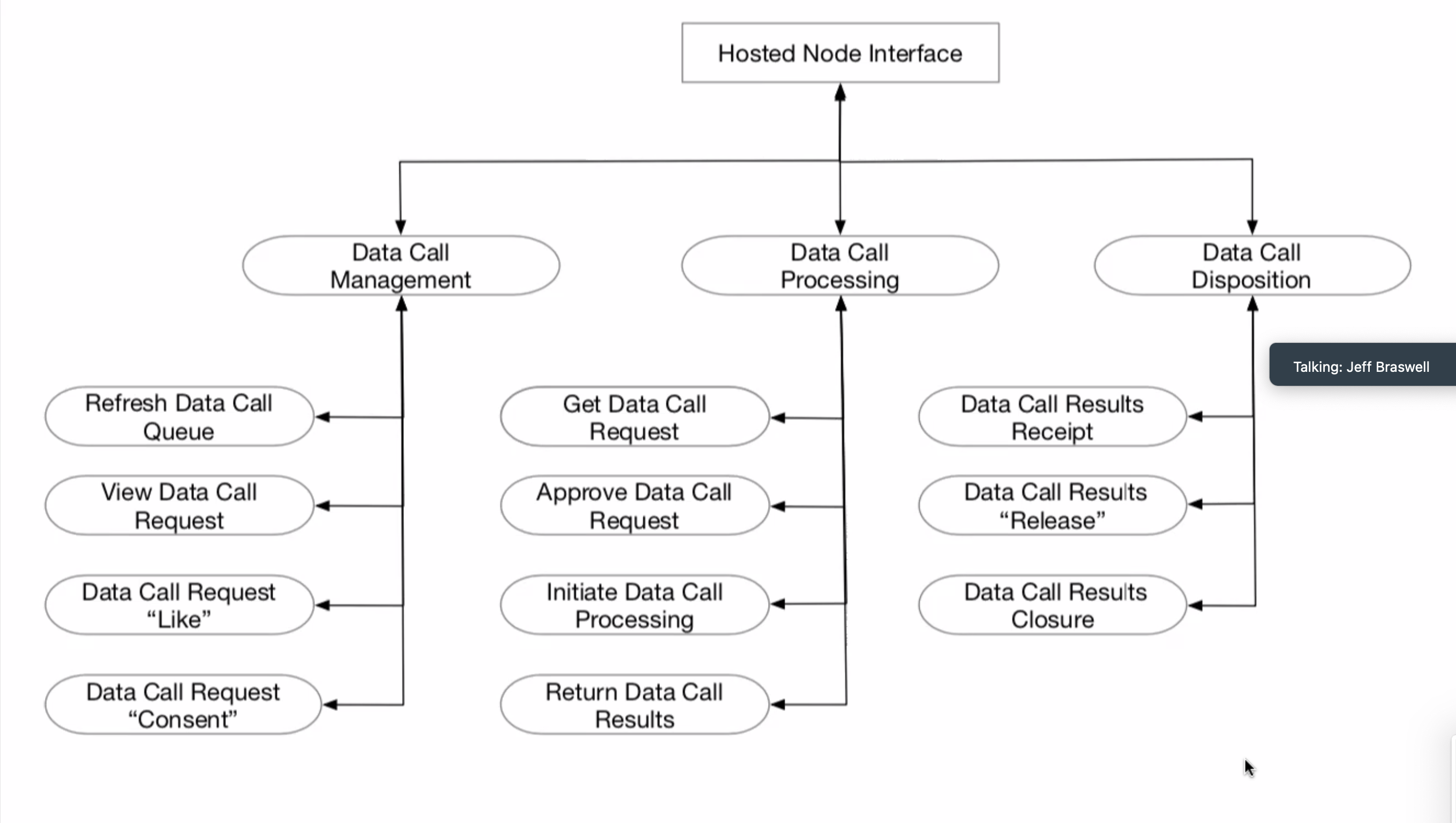
Mr. Braswell presented a diagram w/various logical endpoints of an interface for API and the various types of resources that might be used. One of the central ideas behind this: this can and should work whether these are call-ins or call-outs. The diagram illustrates that there are other types of interactions in the adapter to the hosted node in addition to just processing the data extract:
- Details of how we perform the extract can be summarized by the two ellipses at the bottom and the middle <initiate data call processing> and <return data call results>.
- The diagram illustrates something fundamental: Since we are positing the notion of an interface to a hosted node, some of the functions that exist in the node itself - re: looking at the queue of requests or the UI that interacts with one of the Kubernetes containers to talk to the chain code - this particular function (knowing what the requests are/what's in the queue) needs to be proxied out into some form of API call in this interface. JB is calling this "data call management" - i.e., the notion of refreshing data call queue, is the equivalent of getting the current list of data calls that might be seen in the UI on the actual node, but we aren't assuming that someone has this UI because they aren't running that node, and they lack the container in the Kubernetes cluster. We could actually call out and say "please let me know what all the outstanding data calls are," which will yield a list - and if we want to look at a particular one, that view data call request may give us the ability to look into the detail of that or make a call out to say 'let me know what this request is.'
- Like and consent are notions that precede actual notions of the extract. JB has put the extract processing under data call processing and we start this with 'get data call request.' Whether or not this is something that is called in or called out, there is then the notion of approving data call request - part of the validation process. Making sure we want to run it. This doesn't have to be an API call, but we should have the option not to run it. We can also at least acknowledge it and say to the other side "I'm beginning to run it."
- Returning the results completes this process. The final column, Data Call Disposition, has a notion of Data Call Results received - did you get it? (Confirmation of receipt)
- Two-phased consent - after is all is said and done, is it okay to release the results to this carrier? Total aggregated results etc. Called 'release and final consent.'
- Results of disposition of data call - last step - what is to be done with resultant data? Is it deleted? Is it stored? Is it archived? (i.e., Closure)
- Overall, this diagram shows, logically/conceptually, what some of the major interactions might be in the course of the life cycle/data calls, that would abstract this directly through a hosted node UI, without the use of the UI directly into the chain code. There does need to be some type of agent or endpoints that will service this interface regardless of whether it is pulled or pushed.
Discussion Ensued
KS: Raised question of what is in hosted node vs what is in carrier's world. Proposed that we may have great difficulty installing all this on a carrier.
JM: The reason on the data call management side, that the refresh data call queue exists, as a message, is that x user doesn't have access to the Kubernetes running on the node that queries the chain code to get the outstanding request... So all of this has to do with messaging that is talking to the hosted node via the interface. The adapter says what are the outstanding requests, sends back a list of current requests - a roster - in message form. Kubernetes would be on the other side of the hosted node interface. We can do this with a very simple script that looks at a table or a file?
JM: Questions. We say "hosted node" but what is the official logical name of the other node?
JB: This is the side of the interface that would be the adapter, that would know what to do, to talk to the hosted node.
JM: There is a box we call the carrier node - and it has an entry point/API with various functions. But what is the name of the thing calling this?
JB: If one has one's own node, one doesn't necessarily need the hosted node interface. One can perform these tasks directly. But for the purpose of the carriers that don't want to host their own node, the concept of the hosted node - this is the fabric node that runs on the network, but the fabric talks to it, so it isn't necessary to maintain that in one's own carrier space.
JB: all of these mechanisms sit in the adapter on the carrier side.
KS: We need to refactor the naming of this - the blue box that makes it work, that's in the carrier - more than just the adapter, it may be necessary to deploy some of these other pieces.
JM: What entity calls the API? Who is the client of this?
KS: As we're doing an extraction for a data call, we're interacting with this part x to say "I consent.' Upon consent, the chain code says "I need to get data from the carrier." There is a trigger - something's listening in a pod in Kubernetes (a trigger). This is an application called the extraction processor that lives in Kubernetes in the hosted node, right next to the chain code (JB: a node on the network - has functions that interact with HL fabric). JB: consent has to come from carrier, can't come from hosted node.
KS: Yes it can, because the carrier's interacting with the hosted node... There is a UI, we have to use the UI running on the hosted node to interact with the data call. That's what this diagram depicts.
JB: I'm assuming that it isn't necessarily going be that easier for a carrier who doesn't have the node to access the UI that is running in the node - this may present security issue for getting access to the node?
KS: This can definitely present security issues, it's just a question of getting permissions. Basically it's SAAS at this point, something like an Atlassian Confluence. Just interacting with the system, it's hosted elsewhere. That's what this picture says - something running over there has a UI that we interact with, via permissions from the host. At some point it reaches out, because it needs to run an extraction, sends the extraction across, and that is when this takes place.
JB: We shouldn't assume implementations of full function node, in cases where you're running your own node with the UI and the different containers that make up that cluster, if there's a dependency on getting access to this, the interface btwn a carrier and the hosted node as a svc could be done with this interface, so that you don't have any dependency on the implementation of the hosted node but you do have an interface to talk to. Ergo, whether it's a call out or call in, it can be terms of not necessarily having access to components inside the hosted noded self.
KS: It's not receiving from the UI, it's receiving from a module running in the hosted node - the extraction processor program, that grabs the data call, takes the extraction pattern out, sends to the adapter, and says 'Please run this, I will take the results and put the results on this channel so it goes through the analytics node." The results are then transformed into a report by analytics node. We're splitting out the execution of that extraction pattern into the carrier world, because that's a stack we think will run in the carrier.
PA: Hosted node will send a request for data to the member's enterprise, member's enterprise returns the data back to the hosted nodes, and the operator will utilize UI coming from the hosted node. No operator will be operating on the enterprise.
KS: Actually if the enterprise wants to run the whole stack, this should be an option. We've laid out the above because we want to get a tech stack that is approachable and one that includes HL fabric isn't approachable in the short term.
JM: OpenIDL as a service is not a hosted node - but an environment in which you can host any number of member nodes.
JB: But there would be a hosted node for each carrier.
that if there's a dependency on getting access to this...
Mon., Oct. 24, 2022
Recap
KS: Last meeting - drawing boxes and labeling what is what - i.e., what is openIDL, non-openIDL
(Mr. Sayers presented this diagram again)
KS: We reviewed adapter piece - aka openIDL Data Module - this is the piece provided by openIDL to run in carrier's cloud, and we also have hosted control module that could be in cloud also but is separable (per the Travelers approach). Some concerns about what information/data goes across this line on the open internet. The security needs of this will be revisited.
KS: We also talked about the extraction processor itself, and executing that script - there may be some functions as part of this. We've discussed about running a script that establishes those functions first - these scripts will use these functions repeatedly, we build them before query time. Parsing functions in - will change the delimiter and make it much more complicated. Executing as a set up script means alleviating the need to parse it every single time.
JM: We can either run it as a prescript or build it into database structure itself. (KS agreed). Pros and cons to each approach. Part of extraction process review - reading and signing off. Increases demands of individual on front end. If we had both we would have far more flexibility but incredibly complex engineering.
DH: Biggest concern - what is going out the door, and how have those attributes been created.
JM: Any function we define should have business requirements from which derived, and a unique identifier - then when a coder comes in there is greater clarity. Code has to do what requirements say it should do. By having it in the DB layer, we test it assiduously. Traceability with code + stability. The opposite problem if we put these functions into the extraction pattern.
JM: In final design, one of rules has to be... (clarify)
KS: do we have a sandbox that we can define and protect around these formulas?
PA: Shared screen - and formulas for EP, Car Years, Incurred Count, Incurred Loss. All these calculated based on spreadsheet Mr. Harris made. PA went through query that he uses to make car years with various included functions (car years, earned premium, incurred count, etc.)
KS: Can we constraint the go to the EP schema?
PA: Yes, depending on who makes the stored procedure, but we will absolutely need manual review. We can get very explicit about which permissions we give to which users. Question: do we want to just be doing an extract to the EP so function can be work on that instead?
JM: Functions in EP schema make more sense
PA: Do we want to replicate the auto premium table from the base schema into the EP schema? JM: No.
PA: We get the procedure which exists in openIDL ep schema - running a select on a base table. Is this a problem?
JM: No, and this is why we want functions, procedures, etc. in ep schema - so we can restrict hDS functions. It's a safeguard.
PA: We will not replicate the base tables, then.
PA: Running through table - it begins to break up information. Still looking at how to break out physical damage into comprehensive & collison.
KS: We have the ability in a best case to get functions into code - present and available as part of EP schema. Can we say all functions we be only against ep schema?
JM: They will not have manipulative authority against the HDS. There is a safeguard even if we put functions in the call. We will have hundreds of functions over the years. We want to allow for a few novel functions in the calls but don't want to stuff everything into extraction patterns. We should provide room for both.
KS: Where is constraint on HDS manipulations?
JM: We would grant select to EP schema, but wouldn't grant anything else. The EP data only has read access to the HDS.
KS: We execute prescript as a script, the parse extraction script into commands and run the commands. Can we put another delimiter in there that delimits everything?
PA: Question - currently has a premium table, a loss table and various functions. can write a bash script, -e., etc., but how should we structure deployment?
JM: Many small scripts with one orchestrator across it (orchestrator can be a bash script).
KS: Reservations about bash given about its openness.
JM: At the low level of hitting a database with files, there isn't the need for an interpreter associated with Javascript.
PA: will develop bash script for this and also work on breaking out all rows. Will run multiple psql commands (terminal commands for accessing database), create databases, create schemas. Script will be very carefully regulated - this will be core database structure. Very carefully & deliberately infrastructured.
PA: Provisioning the server will mean doing git clone.
JM: In looking at bootstrapping, we need to say do we have a Linux server to work on? Then create user, create schema, etc. This is bootstrapping. We need to determine if we want to pre-containerize.
JB: Setup/configuration before we even perform first extraction.
KS: Extraction pattern is not bash script. Just SQL.
JM: We have to build module on the carrier before hand. What is the extraction pattern allowed to assume is already in existence? Set of well-defined functions.
How does extraction pattern look?
KS: Two text docs - one creates functions that aren't there yet, and one that can parse individual commands; each one executed in turn. Extraction is still in one file - command separated by semicolons.
KS: Asked how we're executing extraction?
PA: A service user will be installing database... A javascript wrapper will connect with credentials for service user. Giant fixed width data array will come back. Java script - executing this against database.
PA: The one element we don't care about - definitely connecting not with local host to lambda function.
PA: Spike POC needed to run a javascript code against the database - PA is happy to develop this.
JM: Node_JS prompts interesting discussion regarding AWS Services - quite a big question. Will I build with server lists or not?
JB: Some carriers may not use containers on their sides.
JM: Containers however tend to be more universal. If we build this for Linux, and if we're comfortable doing so, we can build in both containerized and native versions.
KS: Difficulty will arise in connecting to API
PA: Two options API gateway or Javascript Express.
JM: We should lean more heavily toward Javascript - basic linux.
KS: begin with reference implementation using AWS. As long as what we're replacing in ref. implementation is obvious, it should be fine.
JM: Suggestion to PA - build postgreSQL database on Linux server. (go back in recording for elaboration).
PA: In the past, he has used Python Flask to do API, and manipulate exposing the port/doing the framework.
JM: Node_js libraries should include the framework.
PA: Would probably want to use express.
JM: ???? Send and receive on the same port
JM: If we have 30 parameters and all are defined, it's exposed. We'll get e.g., 25 returned values. Humble, more flexible version - any characters should be capable of being validated. Caller needs to know how to parse Json.
PA: In payload, JM wants to put json in return value
JM: Or we tell it that it has multiple paths. One Json string in, one big string out. Json validation necessary. Is this okay? String out is result set, we need to agree on how to jsonize this etc. We also have to decide how to paginate. We need to define page - API calls are not meant to hit a browser. We will hit against a result set that is ridiculously large
KS: Going across carriers and combining at end - different zip codes, etc. - we may end up with massive results.
JB: At some point we need flow control through pagination
JM: Recommends that we table it - lg strings in and out. Json schema at least for input. Prescribed format.
JB: For output, if we get into doing different type of report we will say x for header...
Time | Item | Who | Notes |
|---|---|---|---|
Overview
Content Tools