openIDL Navigation
Page History
...
that if there's a dependency on getting access to this...
Mon., Oct. 24, 2022
Recap
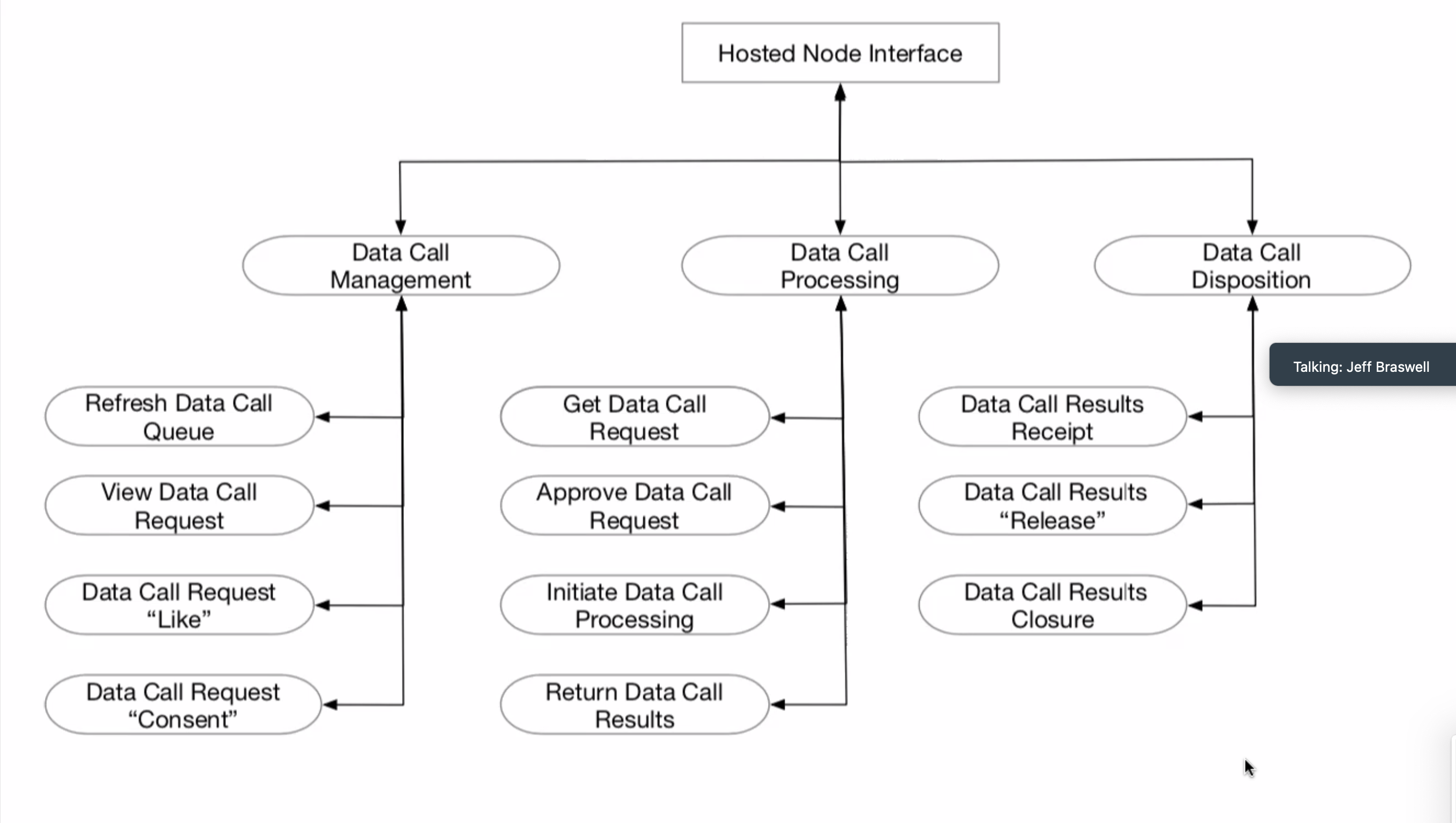
KS: Last meeting - drawing boxes and labeling what is what - i.e., what is openIDL, non-openIDL
(Mr. Sayers presented this diagram again)
KS: We reviewed adapter piece - aka openIDL Data Module - this is the piece provided by openIDL to run in carrier's cloud, and we also have hosted control module that could be in cloud also but is separable (per the Travelers approach). Some concerns about what information/data goes across this line on the open internet. The security needs of this will be revisited.
KS: We also talked about the extraction processor itself, and executing that script - there may be some functions as part of this. We've discussed about running a script that establishes those functions first - these scripts will use these functions repeatedly, we build them before query time. Parsing functions in - will change the delimiter and make it much more complicated. Executing as a set up script means alleviating the need to parse it every single time.
JM: We can either run it as a prescript or build it into database structure itself. (KS agreed). Pros and cons to each approach. Part of extraction process review - reading and signing off. Increases demands of individual on front end. If we had both we would have far more flexibility but incredibly complex engineering.
DH: Biggest concern - what is going out the door, and how have those attributes been created.
JM: Any function we define should have business requirements from which derived, and a unique identifier - then when a coder comes in there is greater clarity. Code has to do what requirements say it should do. By having it in the DB layer, we test it assiduously. Traceability with code + stability. The opposite problem if we put these functions into the extraction pattern.
JM: In final design, one of rules has to be... (clarify)
KS: do we have a sandbox that we can define and protect around these formulas?
PA: Shared screen - and formulas for EP, Car Years, Incurred Count, Incurred Loss. All these calculated based on spreadsheet Mr. Harris made. PA went through query that he uses to make car years with various included functions (car years, earned premium, incurred count, etc.)
KS: Can we constraint the go to the EP schema?
PA: Yes, depending on who makes the stored procedure, but we will absolutely need manual review. We can get very explicit about which permissions we give to which users. Question: do we want to just be doing an extract to the EP so function can be work on that instead?
JM: Functions in EP schema make more sense
PA: Do we want to replicate the auto premium table from the base schema into the EP schema? JM: No.
PA: We get the procedure which exists in openIDL ep schema - running a select on a base table. Is this a problem?
JM: No, and this is why we want functions, procedures, etc. in ep schema - so we can restrict hDS functions. It's a safeguard.
PA: We will not replicate the base tables, then.
PA: Running through table - it begins to break up information. Still looking at how to break out physical damage into comprehensive & collison.
KS: We have the ability in a best case to get functions into code - present and available as part of EP schema. Can we say all functions we be only against ep schema?
JM: They will not have manipulative authority against the HDS. There is a safeguard even if we put functions in the call. We will have hundreds of functions over the years. We want to allow for a few novel functions in the calls but don't want to stuff everything into extraction patterns. We should provide room for both.
KS: Where is constraint on HDS manipulations?
JM: We would grant select to EP schema, but wouldn't grant anything else. The EP data only has read access to the HDS.
KS: We execute prescript as a script, the parse extraction script into commands and run the commands. Can we put another delimiter in there that delimits everything?
PA: Question - currently has a premium table, a loss table and various functions. can write a bash script, -e., etc., but how should we structure deployment?
JM: Many small scripts with one orchestrator across it (orchestrator can be a bash script).
KS: Reservations about bash given about its openness.
JM: At the low level of hitting a database with files, there isn't the need for an interpreter associated with Javascript.
PA: will develop bash script for this and also work on breaking out all rows. Will run multiple psql commands (terminal commands for accessing database), create databases, create schemas. Script will be very carefully regulated - this will be core database structure. Very carefully & deliberately infrastructured.
PA: Provisioning the server will mean doing git clone.
JM: In looking at bootstrapping, we need to say do we have a Linux server to work on? Then create user, create schema, etc. This is bootstrapping. We need to determine if we want to pre-containerize.
JB: Setup/configuration before we even perform first extraction.
KS: Extraction pattern is not bash script. Just SQL.
JM: We have to build module on the carrier before hand. What is the extraction pattern allowed to assume is already in existence? Set of well-defined functions.
How does extraction pattern look?
KS: Two text docs - one creates functions that aren't there yet, and one that can parse individual commands; each one executed in turn. Extraction is still in one file - command separated by semicolons.
KS: Asked how we're executing extraction?
PA: A service user will be installing database... A javascript wrapper will connect with credentials for service user. Giant fixed width data array will come back. Java script - executing this against database.
PA: The one element we don't care about - definitely connecting not with local host to lambda function.
PA: Spike POC needed to run a javascript code against the database - PA is happy to develop this.
JM: Node_JS prompts interesting discussion regarding AWS Services - quite a big question. Will I build with server lists or not?
JB: Some carriers may not use containers on their sides.
JM: Containers however tend to be more universal. If we build this for Linux, and if we're comfortable doing so, we can build in both containerized and native versions.
KS: Difficulty will arise in connecting to API
PA: Two options API gateway or Javascript Express.
JM: We should lean more heavily toward Javascript - basic linux.
KS: begin with reference implementation using AWS. As long as what we're replacing in ref. implementation is obvious, it should be fine.
JM: Suggestion to PA - build postgreSQL database on Linux server. (go back in recording for elaboration).
PA: In the past, he has used Python Flask to do API, and manipulate exposing the port/doing the framework.
JM: Node_js libraries should include the framework.
PA: Would probably want to use express.
JM: ???? Send and receive on the same port
JM: If we have 30 parameters and all are defined, it's exposed. We'll get e.g., 25 returned values. Humble, more flexible version - any characters should be capable of being validated. Caller needs to know how to parse Json.
PA: In payload, JM wants to put json in return value
JM: Or we tell it that it has multiple paths. One Json string in, one big string out. Json validation necessary. Is this okay? String out is result set, we need to agree on how to jsonize this etc. We also have to decide how to paginate. We need to define page - API calls are not meant to hit a browser. We will hit against a result set that is ridiculously large
KS: Going across carriers and combining at end - different zip codes, etc. - we may end up with massive results.
JB: At some point we need flow control through pagination
JM: Recommends that we table it - lg strings in and out. Json schema at least for input. Prescribed format.
JB: For output, if we get into doing different type of report we will say x for header...
Time | Item | Who | Notes |
|---|---|---|---|
Overview
Content Tools