openIDL Navigation
Page History
...
This is a weekly series for The Regulatory Reporting Data Model Working Group. The RRDMWG is a collaborative group of insurers, regulators and other insurance industry innovators dedicated to the development of data models that will support regulatory reporting through an openIDL node. The data models to be developed will reflect a greater synchronization of data for insurer statistical and financial data and a consistent methodology that insurers and regulators can leverage to modernize the data reporting environment. The models developed will be reported to the Regulatory Reporting Steering Committee for approval for publication as an open-source data model.
openIDL Community is inviting you to a scheduled Zoom meeting.
Join Zoom Meeting
https://zoom.us/j/98908804279?pwd=Q1FGcFhUQk5RMEpkaVlFTWtXb09jQT09
Meeting ID: 989 0880 4279
Passcode: 740215
One tap mobile
+16699006833,,98908804279# US (San Jose)
+12532158782,,98908804279# US (Tacoma)
Dial by your location
+1 669 900 6833 US (San Jose)
+1 253 215 8782 US (Tacoma)
+1 346 248 7799 US (Houston)
+1 929 205 6099 US (New York)
+1 301 715 8592 US (Washington DC)
+1 312 626 6799 US (Chicago)
888 788 0099 US Toll-free
877 853 5247 US Toll-free
Meeting ID: 989 0880 4279
Find your local number: https://zoom.us/u/aAqJFpt9B
| View file | ||||
|---|---|---|---|---|
|
Minutes
Joseph Nibbert
Reggie Scarpa
Mike Nurse
Lanaya Nelson
Jenny Tornquist
Kevin Petruzielo
Libby Crews
I. General Updates - Peter Antley
A. Most of the reference tables done and the first level of the views put together
B. Code values shouldn't change much.
C. Test data sparsely populated stat records - had to rethink loading strategy given the presence of some nulls.
...
D. Today - GUI and business experience re: uploading data to idl
E. Recreating the auto coverage report - making a conversion based on what James Madison limned (below) - shouldn't be a heavy lift.
II. Data Discussion - James Madison
A. Solid reference table system and change management approach exists at the Hartford - outstanding vetting/overview
- Essence of process is tracking code mapping
- Question - it will help to see what Antley & co. have done in light of forthcoming code decomposition
- Resultant discussion - Antley
- Lucid chart - 22+ ref tables
- Implementation of tables over the week - signif. work
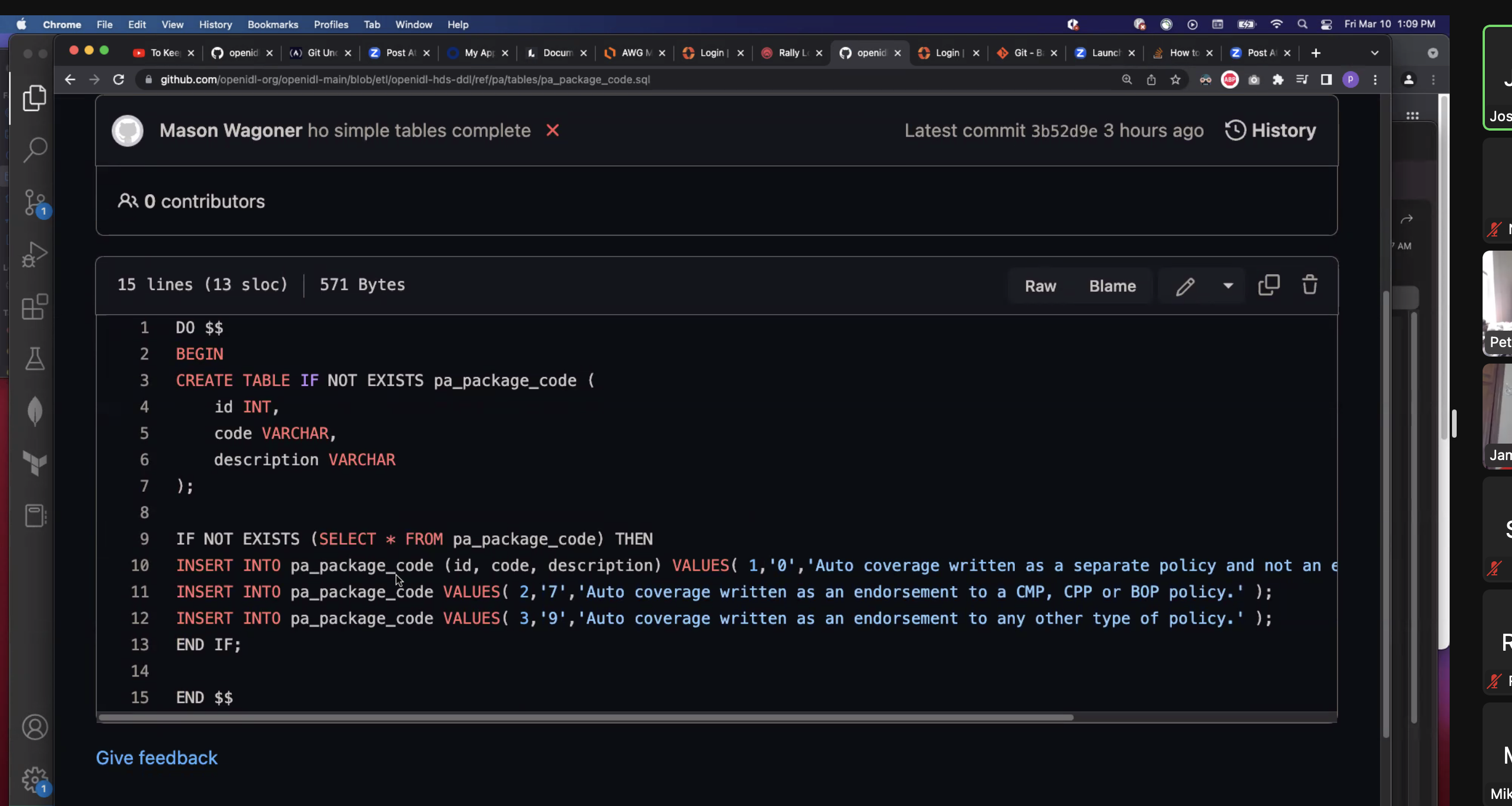
- Presented link to GitHub table accordingly - w/list of all tables (see below)
- MN: some of attributes may cross different lines. Tables shouldn't be reiterated constantly that might have the same information over and over again - this is his concern.
- MN: At Hartford they create common tables that go across all lines w/shared attributes.
- MN: Want to avoid an excess of superfluous tables.
- JB: Elaboration and documentation of data standard
- PA: Started by ingesting coded PNC records - this is GT2 - loss amounts and premium in same row - 22+ code tables ref'd directly from stat plan.
- Package code: assign id, surrogate id, description and reference table. Reference codes directly interpreted from the stat plan
- PA: it grows more complex with areas such as cause of loss - because we start w/cause of loss codes but then see interaction with coverage codes and the like.
- No auto numbering with the tables - all primary keys installed so that they always come out the same way
- Formal documentation on personal auto forthcoming but critical to flag bugs or issues now
- Critical points - Madison
- Declare a key.
- Declare an unexpired date. 12/31/2299? (There's some industry limit, so not 12/31/9999)
- Do eff/exp date on every reference table, even if you think you don't need it. Kimball SCD2.
- Make them externalized CSVs then make a loding module.
- Actually, multi tab Excel and read directly
- JM noted the criticality of defining/declaring a substitute for NULL in sql. Declaring a hard null string/#/date. avoid the null=null pitfall. A hard NULL will help avoid this
- KS: Is it worth addressing this given the amount of work involved?
- JM: if we don't establish this policy early on it doesn't become a strength - and is a liability - we have to null protect throughout.
- KS: What we are talking about is setting a precedence at the outset.
- JM: Advocated that we get this in the queue and pursue it. - Discussion with Peter - agreement to putting on agenda for Mar. 27th AWG.
- Ken: effective use of a hard expiration date has serious repercussions as well - demands exceptions to column after the fact. Third question: what should that hard expiration be? JM: recommended putting this on agenda for Mar. 27th AWG also
- James: wants it instilled into the historical record of discussions for this project
- Discussion requested on external loading of data
B. Business Key/Natural Key Discussion -
- JM: What values do business people look at to uniquely identify one row?
- PA: Policy identifier/claim identifier/actual IDs assigned when loading is done
- JM: we have to agree on how to identify business keys on every table. There should be a business key check - this needs to be reviewed by the AWG
- PA: Unsure if stat plan is compliant with that.
- JM: A key must be put on every field and measured as part of the system.
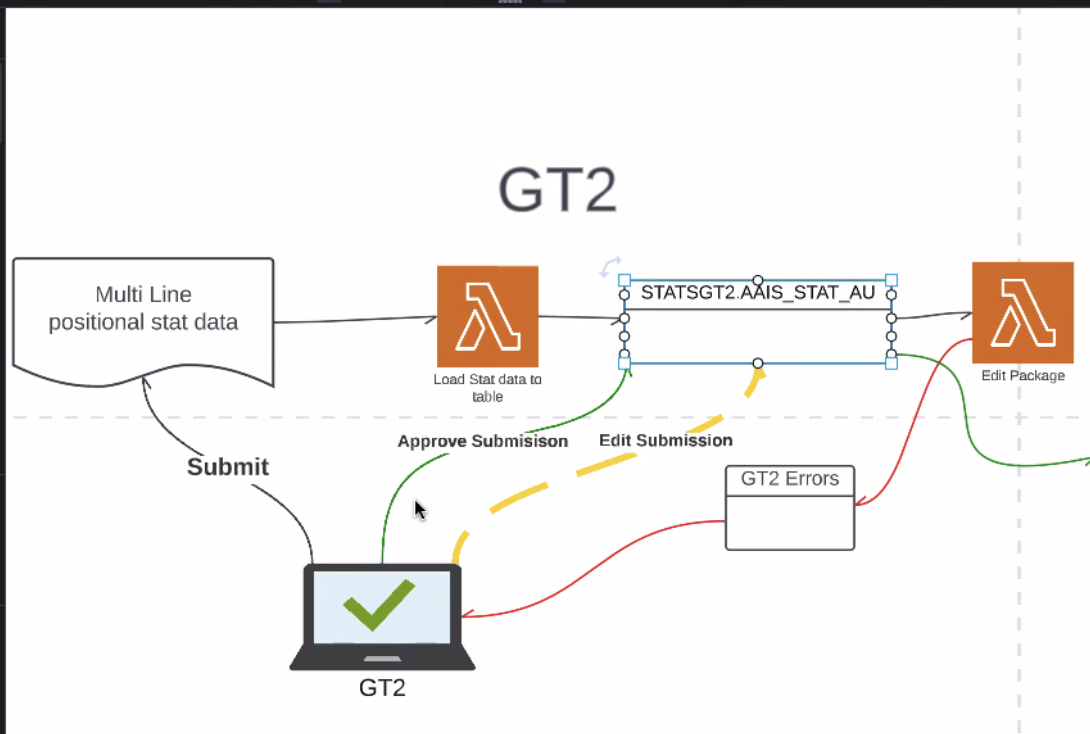
II. SDMA/GT2/Upload Process - and what MVP for application looks like
A. Beginning solutioning for how this will actually work (PA)
B. Needs
- In-line editing to address errors (is this a better option than something the carrier can do to run checks on their own?)
- JM: noted that data should be checked whenever it crosses an ownership boundary
- JM: the HDS is an ownership boundary - and it must be checked before data is given away.
- JM: Accountability of owner of HDS to say yes, my data is legit
- KS: process just allows for fixing at end - and at target not at source. This is only practical. Fixing cannot be done at the target.
- KS: This is stat plan format translated into HDS format - this is happening in the ETL process to get from one to the other.
- Peter provided the following illustration breaking down GT2:
| Time | Item | Who | Notes |
|---|---|---|---|
Action items
Overview
Content Tools