openIDL Navigation
Date

This is a weekly series for The Regulatory Reporting Data Model Working Group. The RRDMWG is a collaborative group of insurers, regulators and other insurance industry innovators dedicated to the development of data models that will support regulatory reporting through an openIDL node. The data models to be developed will reflect a greater synchronization of data for insurer statistical and financial data and a consistent methodology that insurers and regulators can leverage to modernize the data reporting environment. The models developed will be reported to the Regulatory Reporting Steering Committee for approval for publication as an open-source data model.
openIDL Community is inviting you to a scheduled Zoom meeting.
Join Zoom Meeting
https://zoom.us/j/98908804279?pwd=Q1FGcFhUQk5RMEpkaVlFTWtXb09jQT09
Meeting ID: 989 0880 4279
Passcode: 740215
One tap mobile
+16699006833,,98908804279# US (San Jose)
+12532158782,,98908804279# US (Tacoma)
Dial by your location
+1 669 900 6833 US (San Jose)
+1 253 215 8782 US (Tacoma)
+1 346 248 7799 US (Houston)
+1 929 205 6099 US (New York)
+1 301 715 8592 US (Washington DC)
+1 312 626 6799 US (Chicago)
888 788 0099 US Toll-free
877 853 5247 US Toll-free
Meeting ID: 989 0880 4279
Find your local number: https://zoom.us/u/aAqJFpt9B
Attendees
- Nathan Southern
- Sean W. Bohan
- peter antley
- George Bradner
- Sandra Darby
- Greg Williams
- Wenlu Zhang
- Dale Harris
- peter antley
- Reggie Scarpa
- Mike Nurse
- Bourjali Hi
- Brian Hoffman
- Kristin McDonald
- Truman Esmond
- Lori Munn
Allen Thompson
- Kevin Petruzielo
Goals
I. Intro
A. Peter started with LF Anti-Trust Statement
B. Brief Round of Introductions from All Present (Truman, Brian, Dale, etc. intro to Wenlu as new attendee)
C. Recap on auto stat plan reporting progress
II. Recap on AWG/HDS from Sean Bohan
A. Making great progress - numerous requirements laid out and agreed on
B. 2/3 way through initial list of requirements for HDS
III. Main agenda - Peter Antley
A. HDS Task Force
- Earned premium and written premium - 'column zero' (earned premium broken out by various coverages)- presented 2010 NAIC coverage report
- Earned premium - discussed how it is calculated and how these #s come in
- Combination of written premium and accounting dates - yields earned premium over time
- We are working way through new system and determining how it should be oriented to perform.
- At AAIS already preaggregated at quarterly levels
- OpenIDL - come in differently
- Antley created mid-level processing stage - pointing to a broader aggregation that can take place
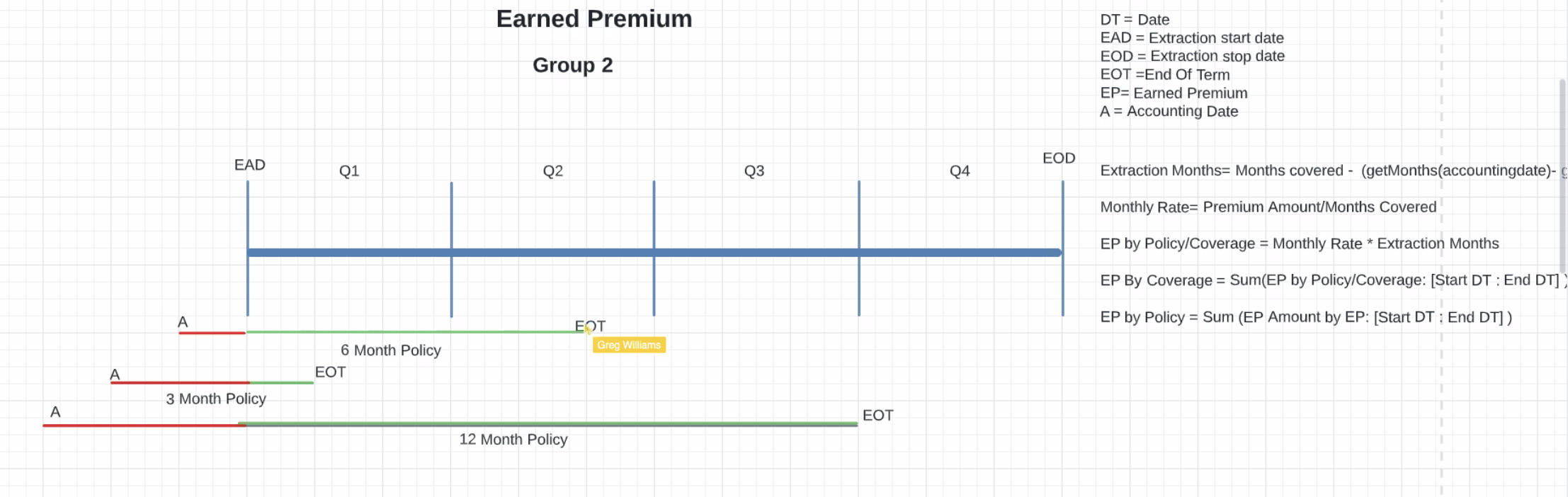
- Pointed to easiest case - group #1 - consists of policies that begin w/accounting date inside the term. Discussed how to read displayed chart. Proposed that we want an earned premium over 1 year.
- Extraction start date beginning of year - EAD - extraction start and stop date are same thing. Extraction stop date at the end. 4 designated end of quarters.
- Below - policies - anything in green successfully earned, red has not been
- Short term and long-term plan - distinguished between the two. Right now: focusing on stat plan as it exists for which we only have accounting date. (Not technically the policy effective date - key preface)
- W/auto only taking one date - called on Mike Nurse to comment.
- The way stat plans are currently written, the accounting date is presumed as effective date. Taken as the start of when earnings calculations begin
- Moving forward we do want to begin collecting a separate policy effective date for purposes of openIDL
- Mr. Antley agreed that we want to limn these/separate out moving forward
- How do we go about calculating earned premium for these records? For each individual record, only one coverage listed - :
- Group 2 - Page 2 -
- What makes this different? Accounting date starting before extraction period and policy is ending in middle of extraction range
13. Presented these equations (see image) for Group 1 and 2
14. Group 3 -
a. Earned premium inside of bounds
b. Same concept of extraction months to determine rate and apply only part of the written to the total earned premium
15. In coming week Antley will be calculating the independent earned premiums of each group - should have it to discuss on Fri. 7/1
IV. Discussion of 7/1 meeting - for July 4th holiday.
Meeting postponed until 7/8.
Discussion items
| Time | Item | Who | Notes |
|---|---|---|---|
Notes
V. Looking ahead
A. Moving ahead to earned loss - proposed by Antley as one option. We have been converting premium records to JSON, decoding them. For loss records, some additional work to be done.
B. They need to be processed and show up perfectly - Antley will be working on laying out this process. Ideally the system should be able to process both record types (earned and premium)
C. Antley proposed a resumption of this subject and a vote on 7/8. Once we get an extraction pattern that can run 3 different cases, much easier and less breaking of new ground.
 GMT20220624-170414_Recording_1920x1080.mp4
GMT20220624-170414_Recording_1920x1080.mp4
Action items
Overview
Content Tools