openIDL Navigation
Page History
...
| SUBJECT | User Authentication for Application Access |
|---|---|
| STATUS | Open |
DECISION | User Authentication is Platform Specific or can it use Okta |
DISCUSSION | The authentication of users must be cloud specific for access to applications because there is no generic authentication provider. - start with aws strategy - cognito - want to offload identiy to identity provider - can we use okta as the main identity management and link it to the underlying provider thus acting as a common api for the applications? |
DATA ARCHITECTURE
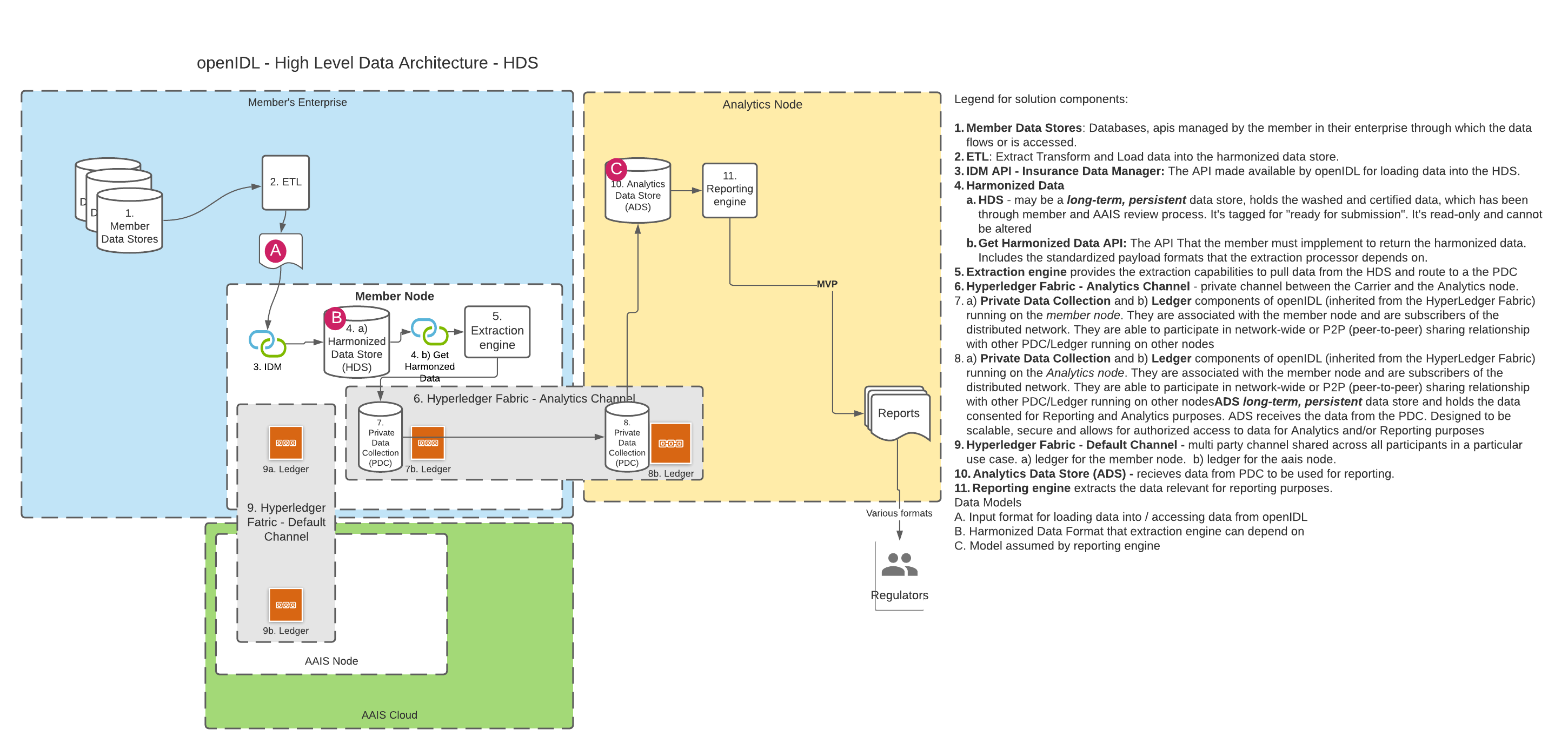
A. Using the HDS DB
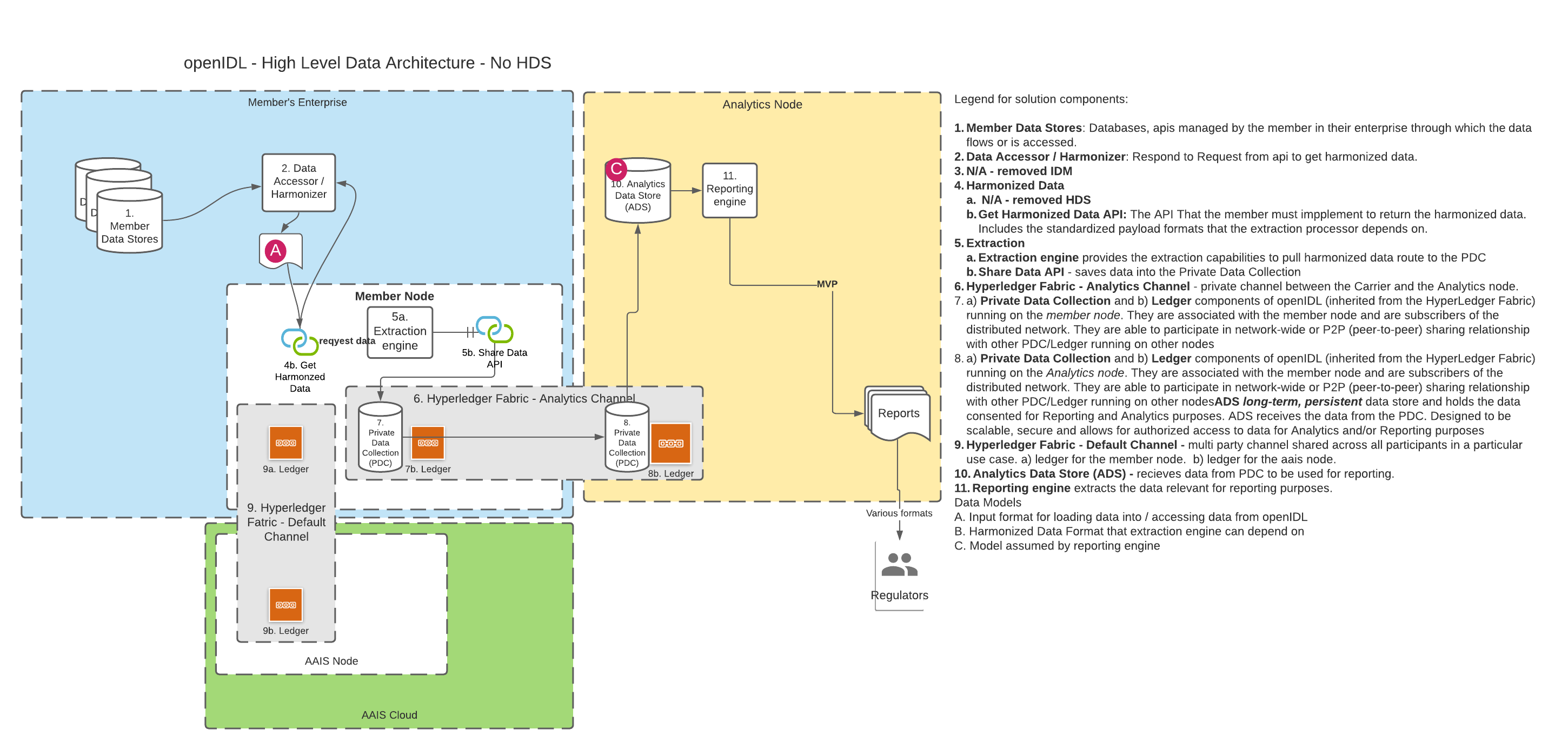
B. Using only the API
| Table of Contents | ||
|---|---|---|
|
| SUBJECT | DA - Extraction Processing |
|---|---|
| STATUS | Open |
DECISION | TBD |
DISCUSSION | In openIDL when a data call (or a stat reporting) is "consented to" by the carrier, the data must first be accessed from somewhere and then transformed into the result format and lastly converted into a report that the target party (usually a regulator) can access or be sent. The transformation of the data from its "harmonized" state to the result state is called the "extraction", "extraction pattern" or "extraction process". Since accessing the data can take multiple forms (see other architecture decision "Harmonized Data", there is some variability in this decision while that decision is undecided. We can assume that the data being accessed for the extraction is "harmonized", meaning for every execution of the extraction on a single node or multiple nodes for a single carrier or multiple carrier, the schema and semantics of the data are known and consistent. Creation and Management of extractions can be organization. For stat reporting, this is the stat-agent (such as AAIS), for data calls, it could be the regulator or a representative like the stat-agent. In either option from the diagrams above, the extraction processor will access the data through an api instead of accessing a database directly. It is proposed that graphQL be considered as the language used to access for extraction and summarization. The extraction processor could apply some correlation to the data, like using an address to look up census data or similar. This means the extraction is more than just a data access. |
| SUBJECT | DA - Harmonized Data Scope |
|---|---|
| STATUS | Proposed |
DECISION | Proposal: data format / schema will be standardized across nodes, for a given use case |
DISCUSSION | The data available for extraction must be normalized for multiple extractions across multiple use cases across multiple members. Is this one single model? Is the data at rest in the same model as the data in motion? |
...
Overview
Content Tools