openIDL Navigation
Page History
...
| SUBJECT | User Authentication for Application Access |
|---|---|
| STATUS | Open |
DECISION | User Authentication is Platform Specific or can it use Okta |
DISCUSSION | The authentication of users must be cloud specific for access to applications because there is no generic authentication provider. - start with aws strategy - cognito - want to offload identiy to identity provider - can we use okta as the main identity management and link it to the underlying provider thus acting as a common api for the applications? |
DATA ARCHITECTURE
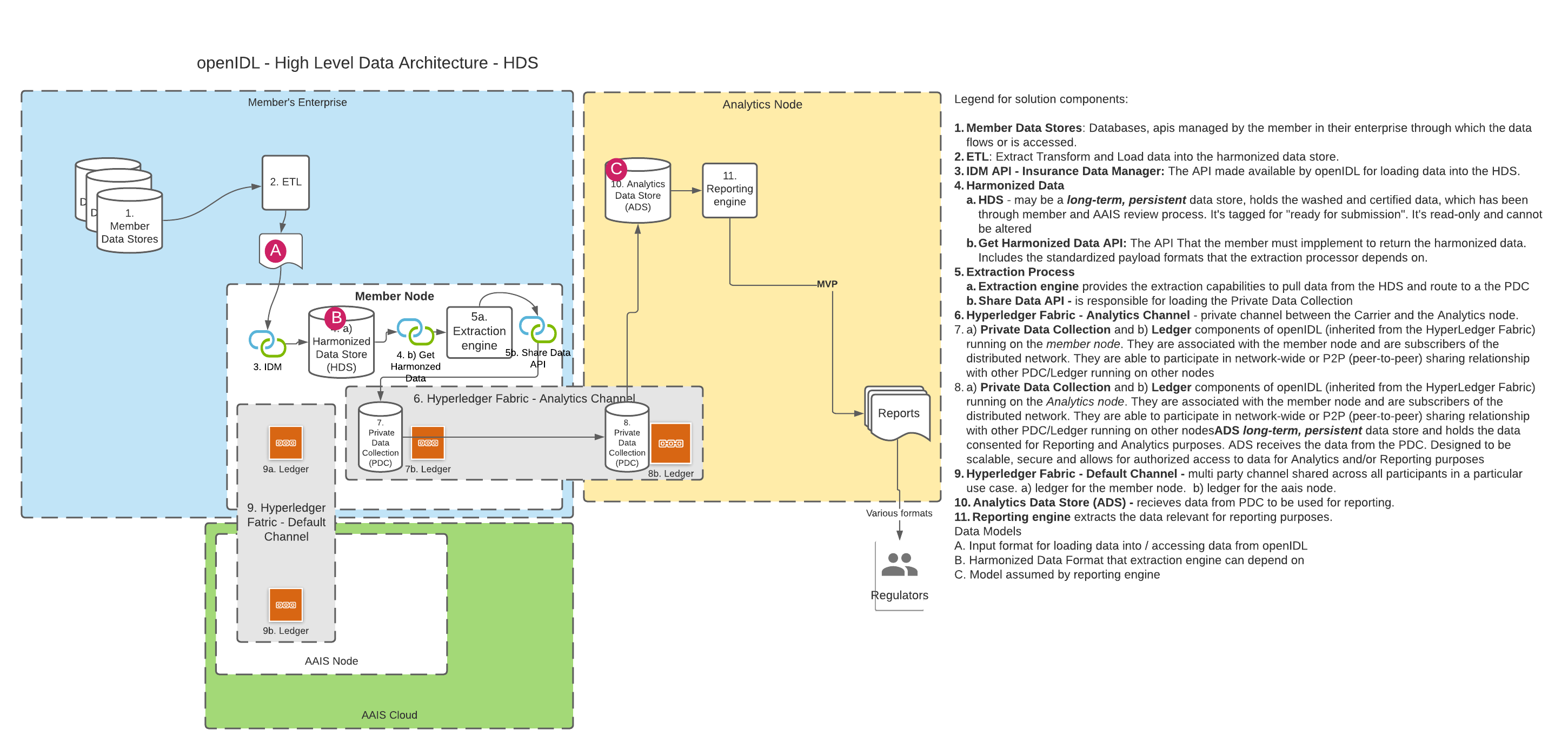
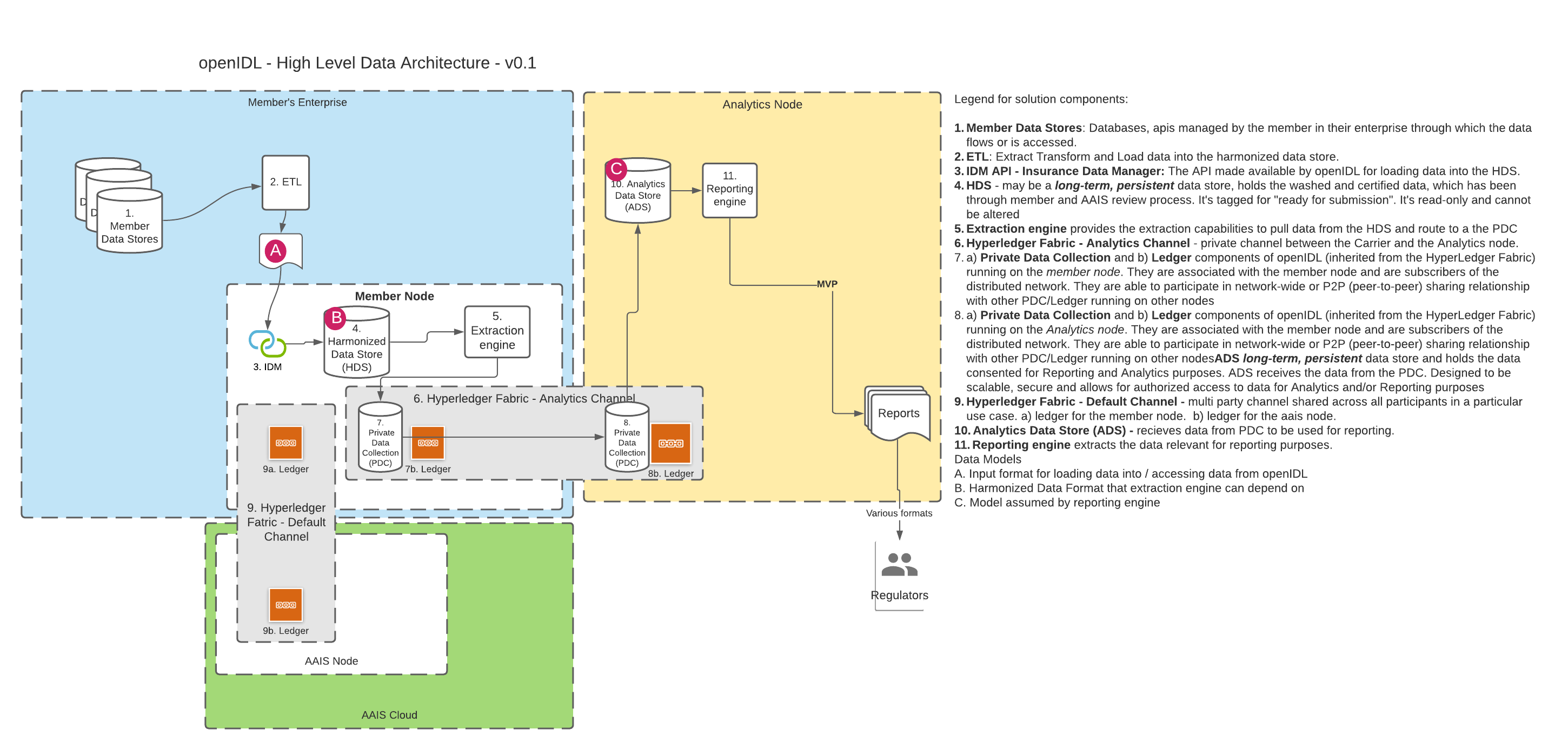
A. Using the HDS DB
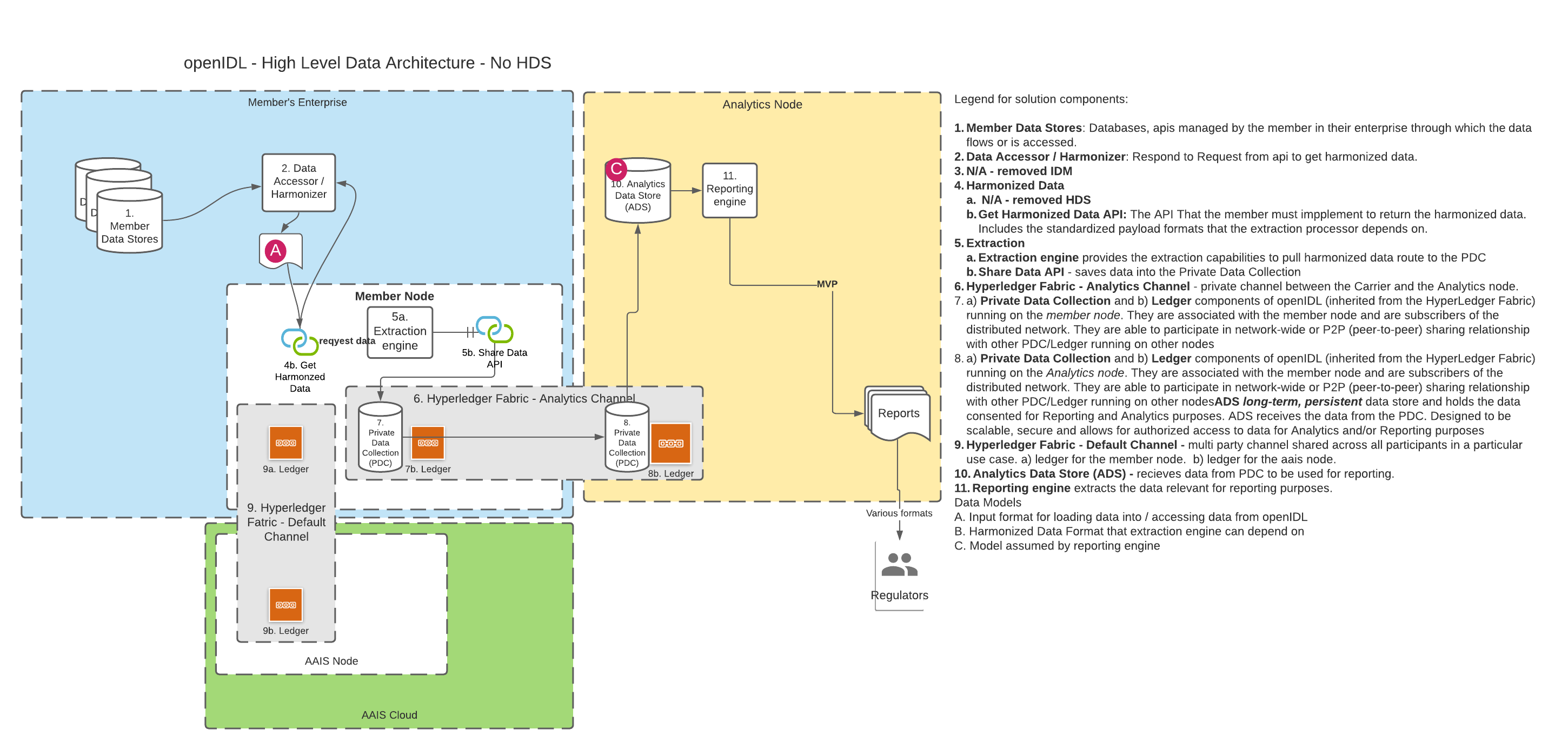
B. Using only the API
| Table of Contents | ||
|---|---|---|
|
| SUBJECT | DA - Extraction Processing |
|---|---|
| STATUS | Open |
DECISION | TBD |
DISCUSSION |
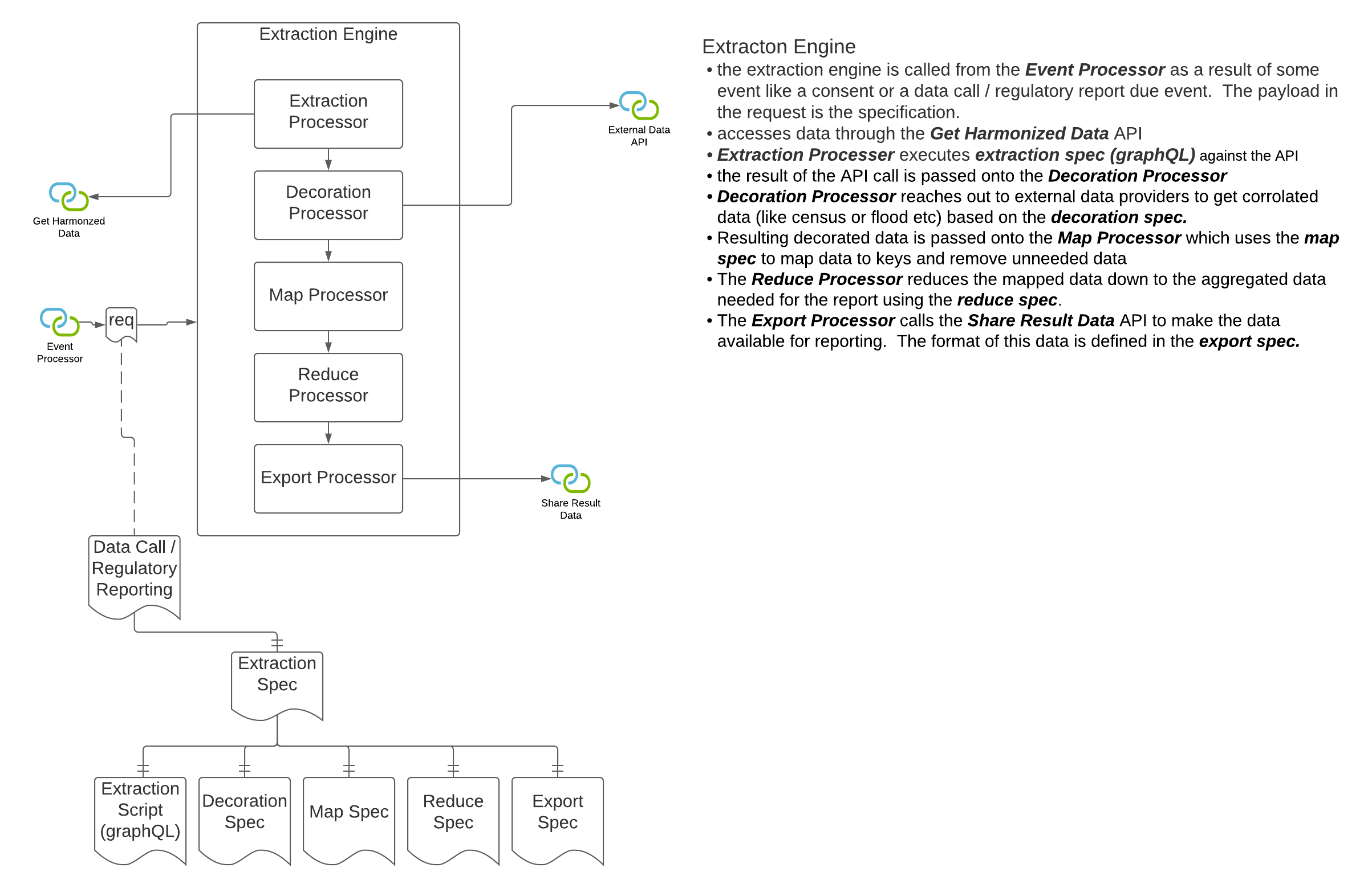
In openIDL when a data call (or a stat reporting) is "consented to" by the carrier, the data must first be accessed from somewhere and then transformed into the result format and lastly converted into a report that the target party (usually a regulator) can access or be sent. The transformation of the data from its "harmonized" state to the result state is called the "extraction", "extraction pattern" or "extraction process". Since accessing the data can take multiple forms (see other architecture decision "Harmonized Data", there is some variability in this decision while that decision is undecided. We can assume that the data being accessed for the extraction is "harmonized", meaning for every execution of the extraction on a single node or multiple nodes for a single carrier or multiple carrier, the schema and semantics of the data are known and consistent. Creation and Management of extractions can be organization specific. For stat reporting, this is the stat-agent (such as AAIS), for data calls, it could be the regulator or a representative like the stat-agent. In either option from the diagrams above, the extraction processor will access the data through an api instead of accessing a database directly. It is proposed that graphQL be considered as the language used to access for extraction and summarization. The extraction processor could apply some correlation to the data, like using an address to look up census data or similar. This means the extraction is more than just a data access. See the diagram above for how this component may be architected. |
| SUBJECT | DA - Harmonized Data Scope |
|---|---|
| SUBJECT | DA - Harmonized Data Format |
| STATUS | Proposed |
DECISION | Proposal: data format / schema will be standardized across nodes, for a given use case |
DISCUSSION | The data available for extraction must be normalized for multiple extractions across multiple use cases across multiple members. Is this one single model? Is the data at rest in the same model as the data in motion? |
| SUBJECT | DA - Harmonized Data Loading / Normalization |
| STATUS | Proposed |
DECISION | Proposal: If the HDS is at rest, the loading of that data is the responsiblity of the member owner of the node. If the HDS is an API, the maintenance of that API and the mapping to other data sources is the responsiblity of the member owner of the node. data format / schema will be standardized across nodes, for a given use case |
DISCUSSION | The data available for extraction must be normalized for multiple extractions across multiple use cases across multiple members. Is this one single model? Is the data at rest in the same model as the data in motion? |
| SUBJECT | DA - Harmonized Data Loading / Normalization | ||
|---|---|---|---|
DISCUSSION |
| ||
| SUBJECT | DA - Harmonized Data Format Governance | ||
| STATUS | Proposed | ||
DECISION | Proposal: data schema, enumeration and the data dictionary will be standardized, and endorsed by the RRSC (and other groups per use case) | DISCUSSION | If the HDS is at rest, the loading of that data is the responsibility of the member owner of the node. If the HDS is an API, the maintenance of that API is the responsibility of the Technical Steering Committee and the mapping to other data sources is the responsibility of the member owner of the node. |
DISCUSSION |
|
| SUBJECT | DA - Harmonized Data Format Governance |
|---|---|
| STATUS | Proposed |
DECISION | Proposal: data schema, enumerations and the data dictionary will be standardized, and endorsed by the RRSC (and other groups per use case) |
DISCUSSION | The Technical Steering Committee, Regulatory Reporting Steering Committee and the Data Model Steering Committee are all possible owners of this. |
| SUBJECT | DA - Harmonized Data Store |
|---|---|
| STATUS | Proposed |
DECISION | Proposal:
|
DISCUSSION | The data available for extraction must be normalized for multiple extractions across multiple use cases across multiple members. Is this one single model? Is this one database? Is this data at rest and/or available through an API |
| SUBJECT | DA - Harmonized Data Access |
|---|---|
| STATUS | Proposed |
DECISION | Proposal:
|
DISCUSSION | If we determine that a standing harmonized store is not required, then we must establish an API with a standardized payload format that can be used to access the data. The member must "certify" that the data is available and quality in order to consent to a data extraction. The consent and certification can be captured on the ledger. The call to the API will come from the extraction processor. The extraction processor can run on the member node. Can the extraction processor run on the Analytics Node? If the extraction runs outside the member node, how does this work? Can it call the API directly? Must we use HLF to "transport" the data? |
| SUBJECT | DA - Harmonized Datastore DBMS Implementation |
|---|---|
| STATUS | Open |
DECISION | Proposal: If the HDS is a physical db inside the node, then the HDS DBMS must support our chosen access language (graphQL?) HDS will be a relational database. It cannot be a noSQL, graph, document DB etc. technical implementation of a HDS is non-prescriptive i.e. it can be MySQL, MS SQL, Oracle etc. |
DISCUSSION | If data is at rest in the harmonized datastore, what is the technology? Does it need to be a single dbms? Should it be noSQL? Can it just be an interface? |
| SUBJECT | DA - Harmonized Data Model |
|---|---|
| STATUS | Open |
DECISION | ?? |
DISCUSSION | The data available for extraction must be normalized for multiple extractions across multiple use cases across multiple carriers. The data must be produced by the carrier from their original sources. Is this an ETL process? What is the format of the load data? Is it the schema of a standing HDS database or is it a messaging format? Is there just one "in transit" model or are there different ones for different contexts? Contexts might be the data call, the line of business, etc. |
| SUBJECT | DA - Export Data Model |
|---|---|
| STATUS | Open |
DECISION | Proposal: The export data model is specific to each use case and must be specified in that data call / regulatory report |
DISCUSSION | The extraction process results in an export of data in an agreed format. The format of this must be defined as part of the specific data call or regulatory report |
| SUBJECT | DA - Harmonized Data Store |
| STATUS | Proposed |
DECISION | Proposal:
|
DISCUSSION | The data available for extraction must be normalized for multiple extractions across multiple use cases across multiple members. Is this one single model? Is this one database? Is this data at rest and/or available through an API |
| SUBJECT | DA - Harmonized Datastore DBMS Implementation |
| STATUS | Open |
DECISION | Proposal: HDS will be a relational database. It cannot be a noSQL, graph, document DB etc. technical implementation of a HDS is non-prescriptive i.e. it can be MySQL, MS SQL, Oracle etc. |
DISCUSSION | If data is at rest in the harmonized datastore, what is the technology? Does it need to be a single dbms? Should it be noSQL? Can it just be an interface? |
| SUBJECT | DA - Harmonized Data Model |
| STATUS | Open |
DECISION | ?? |
DISCUSSION | The data available for extraction must be normalized for multiple extractions across multiple use cases across multiple carriers. The data must be produced by the carrier from their original sources. Is this an ETL process? What is the format of the load data? Is it the schema of a standing HDS database or is it a messaging format? Is there just one "in transit" model or are there different ones for different contexts? Contexts might be the data call, the line of business, etc. |
APPLICATION DEVELOPMENT
| SUBJECT | Common UI Code Management |
|---|---|
| STATUS | Open |
DECISION | Single Application Angular UI Variations will utilize angular libraries |
DISCUSSION | The library will be a different kind of angular app located in the same super library as all apps that use it. This is the approach for the data-call-ui. (openidl-ui and openidl-carrier-ui) For common / shared libraries we will use an npm registry. |
...
Overview
Content Tools