openIDL Navigation
 GMT20230303-180230_Recording_1920x1080.mp4
GMT20230303-180230_Recording_1920x1080.mp4
Date
Attendees
Mike Nurse
Reggie Scarpa
Rambabu Adabala
Joseph Nibert
Hicham Bourjali
Michael Payne
Allen Thompson
Brian Hoffman
Patti Norton-Gatto
Kevin Petruzielo
Ken Sayers

This is a weekly series for The Regulatory Reporting Data Model Working Group. The RRDMWG is a collaborative group of insurers, regulators and other insurance industry innovators dedicated to the development of data models that will support regulatory reporting through an openIDL node. The data models to be developed will reflect a greater synchronization of data for insurer statistical and financial data and a consistent methodology that insurers and regulators can leverage to modernize the data reporting environment. The models developed will be reported to the Regulatory Reporting Steering Committee for approval for publication as an open-source data model.
openIDL Community is inviting you to a scheduled Zoom meeting.
Join Zoom Meeting
https://zoom.us/j/98908804279?pwd=Q1FGcFhUQk5RMEpkaVlFTWtXb09jQT09
Meeting ID: 989 0880 4279
Passcode: 740215
One tap mobile
+16699006833,,98908804279# US (San Jose)
+12532158782,,98908804279# US (Tacoma)
Dial by your location
+1 669 900 6833 US (San Jose)
+1 253 215 8782 US (Tacoma)
+1 346 248 7799 US (Houston)
+1 929 205 6099 US (New York)
+1 301 715 8592 US (Washington DC)
+1 312 626 6799 US (Chicago)
888 788 0099 US Toll-free
877 853 5247 US Toll-free
Meeting ID: 989 0880 4279
Find your local number: https://zoom.us/u/aAqJFpt9B
Minutes
I. Introductory Comments - Peter Antley
A. Welcome to Attendees
B. LF Antitrust Policy
II. Agenda
A. Decoding tables
- Working on these over last week
- Halfway through developing ETL & data layer
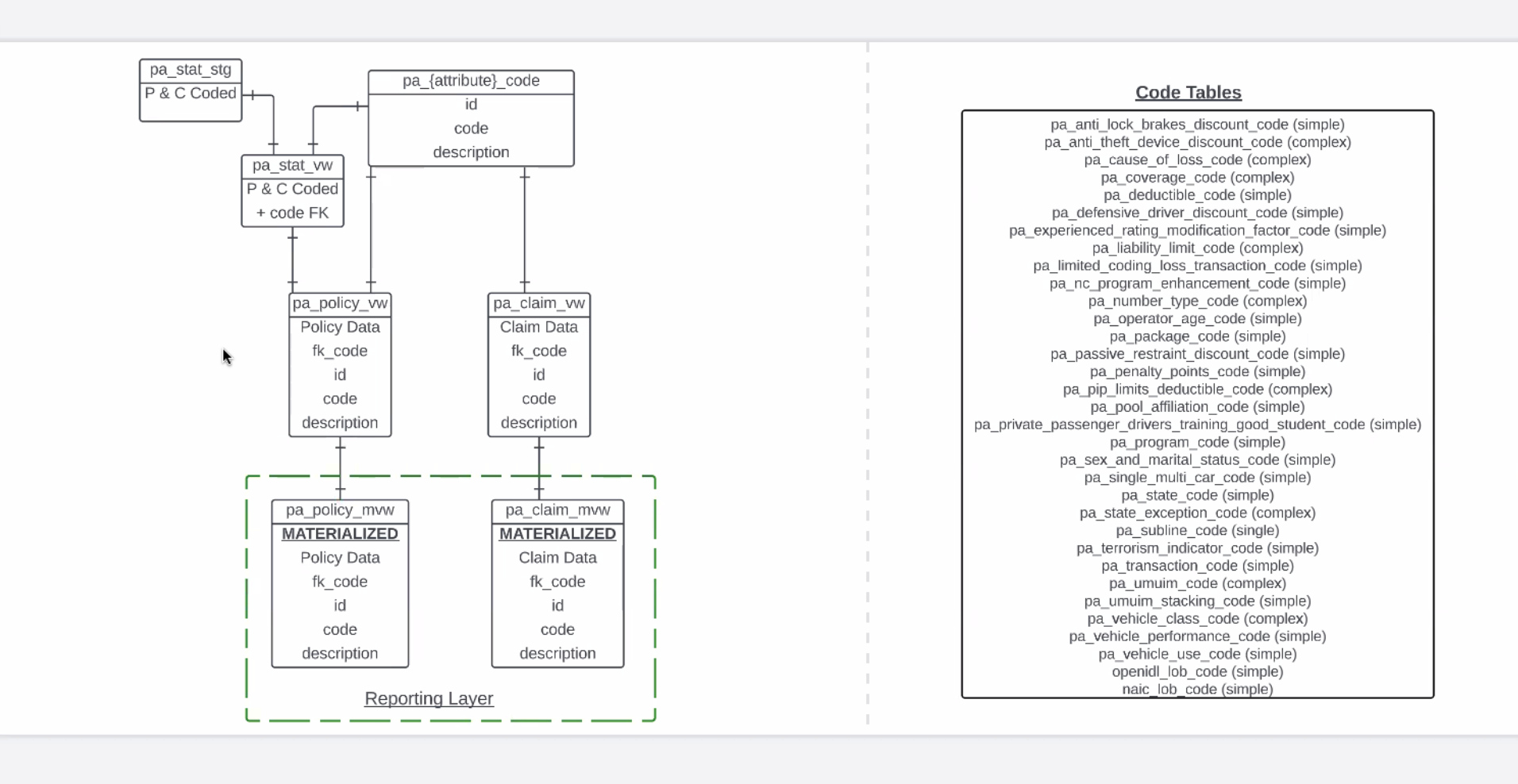
- PA: Pulled up a diagram to illustrate this
- Using code from GT2 - restricted however by its inability to offer in-line editing
- Adding some features on top of this.
- Taking edit package from GT2 and recycled UI & adding new features
- UI - uploading data + edit packages
- GT2 & SDMA do not do decoding
- Utilizing GT2 as outbound table and loading into PA stat (stat table) STG (stage)
- Spend week working on decoding tables - primary key, codes from stat plan and description, a value relating back to the code. (Codes listed in Peter's slide)
- Arkansas, PA & NJ - unique ways to do their coding - so to accommodate this Peter wrote ~5000 lines SQL. Wrapping up these tables today
- Mason is working on a simple script to load this table - so we can get into data testing before UI is ready
- PNC Stat View - utilizing a bunch of joins - foreign keys tied to codes. PA Policy view + PA Claim View. Will have all primary keys, codes and descriptions.
- In querying table - it will have to do all kinds of operations before it loads
- Reporting Layer - will only have two tables - will be a decoded stat plan that has original codes + 2 tables personal auto policy/claim materialized view
- No blockers - should be pulled together next week. Then documentation will follow.
B. Questions regarding this
- Mike Nurse
- Looking holistically at all lines of business - any idea how many tables overall? From a maintenance perspective - a lot of work, no?
- PA: most of stat plans are ~ same length. Most of stat plan values are codes, and every code we have needs to be decoded.
- PA: Current stat plan hasn't changed in stat time. Want to make additive changes w/o breaking changes
- Ken Sayers
- Maintaining tables - how will this be done? Broken down into smaller pieces logically? Time managed? Should not be constant, correct?
- PA: More info to come on this in the near future
- MN: There may be more changes than we anticipate. MN: w/his team, data changed in multiple locations = multiple efforts
- KS: Some of maintenance done automatically - script can be run routinely so not a great deal of hands-on work
- JN: Planning on using flyway that maintains whole history of scripts that are run - a way to ensure that databases are identical. Versioning, updates etc. all maintained in the tool.
- PA: for now we must simplify decoding tables - one table for code.
- PA: many codes are specific to stat lines - other codes will be shared/recycled wherever possible to economize.
- Rambabu Adabala
- How is carrier data maintained tabularly -
- PA: each carrier has their own HDS with corresponding tables
- PA: Data will follow idl message format - then check pkgs to make sure data is valid. Will change data from a positional string to a columned basis
- Dale Harris
- Will tables work in Snowflake?
- DH: PA: yes although the extraction pattern will differ a bit
- PA: possible (maybe) to write the extraction pattern generically and give it more versatility
- PA: Exploration may need to be done re: running it in snowflake, though on many levels this would be a strong fit.
- PA: Amazon Aurora serverless may be the best solution... but could create other issues
- PA: group can workshop this in the forthcoming AWG.
C. Modifications to the above table discussed with Peter, Mason & team, and agreed on.
D. Looking ahead - PA
- Will keep moving forward as planned
- Hope to see an extraction pattern running and executing off of tables by next Friday (3/10) but definitely by 3/17/23
Discussion items
| Time | Item | Who | Notes |
|---|---|---|---|
Action items
Overview
Content Tools